|
In distributed systems sharing is the key word: distributed systems share
from information to cables, frequencies, printers, expensive equipment and more.
Our research group studies efficient ways that can used for different
concurrent computer processes to share information and get coordinated
(Interprocess Synchronization)
but also on efficient and fault-tolerant methods for sharing general resources
in networks and peer-to-peer systems
(Communication, Resource Allocation and Sharing).
Instead of sharing physical resources many users would like to
share views of small "worlds" that they can create together
with colleagues or friends. Our group tries to see how to
realize this in a way that is efficient and guarantees that
people see a good approximation of what is happening in their worlds
(Collaborative Distributed Environments
and Visualization).
Now, if you try to imagine how much digital information is generated in such
complex systems, it is probably easy to get convinced that
information visualization is the way to go to illuminate the
information that the user is interested in
(Information Visualization of Complex Systems).
Research perspectives:
- Exploit locality in sharing and decision-making, aiming at improving performance,
fault-tolerance
- Cross-fertilization with our research results and activities in process
synchronization, to address consistency issues.
- Address trade-off issues and decisions in parameterized quality-of-service, in particular
in network and peer-to-peer communication, synchronization and consistency.
- New methods for (virtual) object realization and multi-peer sharing, using distributed
algorithms and data structures.
|
Example applications:
- Communication systems: router packet scheduling, channel allocation in cellular networks,
information sharing, further resource sharing in mobile communication: data, computational
units/capacity
- Information dissemination, synchronization and buffer management in peer-to-peer systems
- Computer-Supported Cooperative Work
- Simulation and Entertainment
|
Links to our projects/results
-
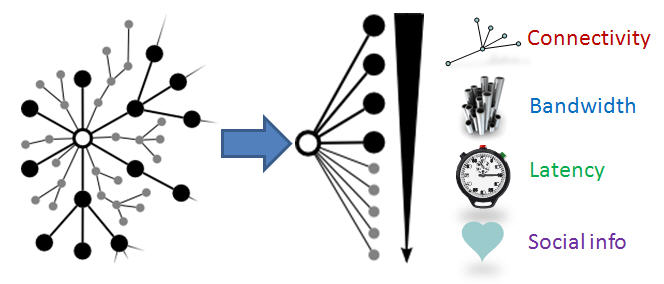 Overlay network formation when nodes have preferences:
A key property of overlay networks, that is going
to play an important part in future networking solutions, is the
peers' ability to establish connections with other peers based on
some suitability metric related to e.g. the node's distance, interests,
recommendations, transaction history or available resources. In this project we employ the use of node satisfaction
to move beyond the classic notion of stable matchings and towards the overlay
network context.
Overlay network formation when nodes have preferences:
A key property of overlay networks, that is going
to play an important part in future networking solutions, is the
peers' ability to establish connections with other peers based on
some suitability metric related to e.g. the node's distance, interests,
recommendations, transaction history or available resources. In this project we employ the use of node satisfaction
to move beyond the classic notion of stable matchings and towards the overlay
network context.
-
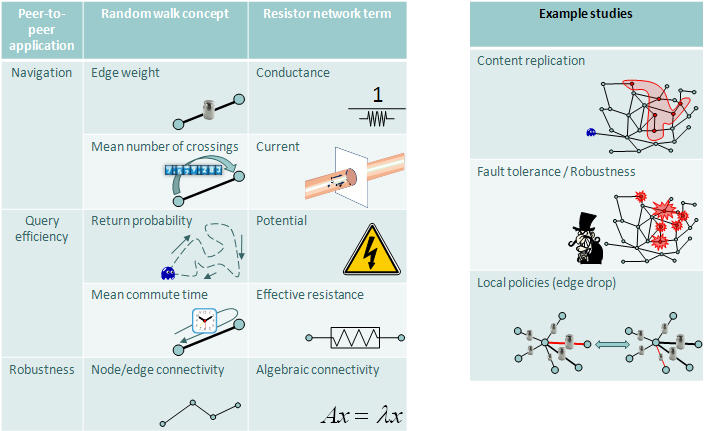 Reasoning about unstructured overlay networks: an electrical circuit-inspired framework:
Unstructured overlay networks coupled with stochastic algorithms are attractive due to low-maintenance requirements
and inherent fault-tolerance and self-organizing properties. However, currently there is a limited selection of
appropriate tools to use in their systematical performance evaluation. This project ties-in a set of diverse
techniques and metrics in a unifying framework, by building on a well-known association between probabilistic tools
such as random walks and simple electrical circuits.
Reasoning about unstructured overlay networks: an electrical circuit-inspired framework:
Unstructured overlay networks coupled with stochastic algorithms are attractive due to low-maintenance requirements
and inherent fault-tolerance and self-organizing properties. However, currently there is a limited selection of
appropriate tools to use in their systematical performance evaluation. This project ties-in a set of diverse
techniques and metrics in a unifying framework, by building on a well-known association between probabilistic tools
such as random walks and simple electrical circuits.
-
 Resource allocation and sharing in network communication:
The project is on how to dynamically allocate resources (codes, channels,
time, computing servers, etc) in a way that accounts for
quality-of-service (QoS) parameters (deadlines, jitter, error probability, bandwidth availability, etc).
The distributed approach has been shown that it is of benefit, especially when
considering fault-tolerance and adaptability.
Resource allocation and sharing in network communication:
The project is on how to dynamically allocate resources (codes, channels,
time, computing servers, etc) in a way that accounts for
quality-of-service (QoS) parameters (deadlines, jitter, error probability, bandwidth availability, etc).
The distributed approach has been shown that it is of benefit, especially when
considering fault-tolerance and adaptability.
-
 Multipeer information dissemination and consistency support:
This project's focus is to study multi-peer info-dissemination and consistency
support for collaborative environments and distributed objects suitable for
such environments, together with efficient data structures and algorithms for
their realization. Application domains which are of interest are telecommunication
systems and distributed infrastructures for collaborative activities.
Multipeer information dissemination and consistency support:
This project's focus is to study multi-peer info-dissemination and consistency
support for collaborative environments and distributed objects suitable for
such environments, together with efficient data structures and algorithms for
their realization. Application domains which are of interest are telecommunication
systems and distributed infrastructures for collaborative activities.
-
 Modeling and design of virtual objects for distributed collaborative environments
Building a collaborative environment implies the challenge of providing consistency between
the view of the users on the one hand and allowing the system to perform well and scale on the other.
A central aim in our research in this project is a general model for such environments. The model
should describe objects and users, interests and possibilities for interest management.
Results include a first such integrated model based on an information-theoretic approach.
Modeling and design of virtual objects for distributed collaborative environments
Building a collaborative environment implies the challenge of providing consistency between
the view of the users on the one hand and allowing the system to perform well and scale on the other.
A central aim in our research in this project is a general model for such environments. The model
should describe objects and users, interests and possibilities for interest management.
Results include a first such integrated model based on an information-theoretic approach.
-
Logical clocks and event ordering in distributed systems:
For many distributed systems it is important to be able to determine the order or
relationship between events occurring in the system. A logical clock algorithm can be used
to get this information. Our research focuses on logical clock algorithms that approximately
tracks the causal order and that use small timestamps and scale to large systems.
 Top of Page Top of Page
Interprocess Coordination and Synchronization
As the size of either the distributed system or the amount of
data the applications have to process increases the need for
large-scale parallelism in all components of a
distributed/parallel software becomes more and more
important. The current synchronization methods used in
distributed/parallel software are based on blocking and are
inherently sequential resulting in significantly reducing the
performance and the overall parallelism of the
distributed/parallel software or the scalability of distributed
systems.
Our Research perspectives:
- Non-blocking/fine-grain synchronization, aiming at increased parallelism, fault-tolerance,
avoiding convoy effects and priority inversion
- Enhancing performance by cooperative scheduling-and-synchronization
|
Example applications:
- Real-time (operating) systems.
- Operating systems, programming languages.
- Embedded-systems synchronization
- Parallel applications from areas, such as biology, chemistry, geosciences,
physics, product design and industrial engineering.
|
Some words on this part of research from Chalmers Nyheter (In Swedish)
Links to our projects/results
-
Understanding the Performance of Concurrent Data Structures on Graphics Processors:
We revisit the design of concurrent data structures - specifically queues - and examine their performance portability with regard to the move from conventional CPUs to graphics processors. We have looked at both lock-based and lock-free algorithms and have, for comparison, implemented and optimized the same algorithms on both graphics processors and multi-core CPUs. Particular interest has been paid to study the difference between the old Tesla and the new Fermi and Kepler architectures in this context. We provide a comprehensive evaluation and analysis of our implementations on all examined platforms. Our results indicate that the queues are in general performance portable, but that platform specific optimizations are possible to increase performance. The Fermi and Kepler GPUs, with optimized atomic operations, are observed to provide excellent scalability for both lock-based and lock-free queues.
-
GPU Software Transactional Memory:
The introduction of general purpose computing on many-core graphics processor
systems, and the general shift in the industry towards parallelism, has created a demand for ease of parallelization.
Software transactional memory (STM) simplifies development of concurrent code by allowing the
programmer to mark sections of code to be executed concurrently and atomically in an optimistic manner.
In contrast to locks,
STMs are easy to compose and do not suffer from deadlocks.
-
Dynamic Load Balancing on Graphics Processors:
We have compared four different dynamic load balancing methods to see which one is most suited to the highly parallel
world of graphics processors. Three of these methods were lock-free and one was lock-based. We evaluated
them on the task of creating an octree partitioning of a set of particles and playing a game of four-in-a-row.
The experiments showed that synchronization
can be very expensive and that new methods that take more advantage of the graphics processors features
and capabilities might be required. They also showed that lock-free methods achieves better performance than
blocking and that they can be made to scale with increased numbers of processing units.
-
 (GPU Quicksort):
The GPU Quicksort Library gives programmers an easy way to increase
sorting performance by harnessing the highly parallel computational
power available in todays graphics cards. Tests shows that it can outperform
highly optimized CPU-based Quicksort with a factor of 8 on cards commonly available in 2007.
Sorting 16 million floating point numbers or integers take less than half a second!
(GPU Quicksort):
The GPU Quicksort Library gives programmers an easy way to increase
sorting performance by harnessing the highly parallel computational
power available in todays graphics cards. Tests shows that it can outperform
highly optimized CPU-based Quicksort with a factor of 8 on cards commonly available in 2007.
Sorting 16 million floating point numbers or integers take less than half a second!
-
 (NOBLE):
A software library of shared data objects. NOBLE contains
efficient non-blocking implementations of several fundamental
shared data structures that are used in practice, such as
stacks, queues, linked lists, priority queues etc. The
library is easy to use and existing programs can easily
adapted to use NOBLE.
(NOBLE):
A software library of shared data objects. NOBLE contains
efficient non-blocking implementations of several fundamental
shared data structures that are used in practice, such as
stacks, queues, linked lists, priority queues etc. The
library is easy to use and existing programs can easily
adapted to use NOBLE.
NOBLE was designed in an effort
to help bridging the gap between research on interprocess
synchronization and use in application and systems software.
-
 (WARPing)
The aim in this project is to study and apply lock/wait-free
methods in real-time systems protocols and study the impact
compared with lock-based methods. One special applications
domain is shared data structure in real-time operating system
kernels. Our expectations and the results achieved so far
include: elimination of priority inversion and of deadlock;
improved fault-tolerance; scalability and uniformity between
uni-processor and multi-processor systems; improved task
execution times and schedulability conditions; no change of
the structure of the existing operating system kernel.
(WARPing)
The aim in this project is to study and apply lock/wait-free
methods in real-time systems protocols and study the impact
compared with lock-based methods. One special applications
domain is shared data structure in real-time operating system
kernels. Our expectations and the results achieved so far
include: elimination of priority inversion and of deadlock;
improved fault-tolerance; scalability and uniformity between
uni-processor and multi-processor systems; improved task
execution times and schedulability conditions; no change of
the structure of the existing operating system kernel.
-
 Lockless-Spark98:
Lockless-Spark98 is a version of the shared memory Spark98 sparse
matrix kernels where the locks used by the original Spark98 Kernels
were replaced by non-blocking synchronization constructs.
Lockless-Spark98:
Lockless-Spark98 is a version of the shared memory Spark98 sparse
matrix kernels where the locks used by the original Spark98 Kernels
were replaced by non-blocking synchronization constructs.
-
Lockless-MiniSPLASH2:
Lockless-MiniSPLASH2 is a lock-free version of part of the
Stanford Parallel Applications for Shared Memory. In this version most
lock-based data structures used by the original SPLASH-2 were
replaced by non blocking synchronisation constructs.
-
NBmalloc:
NBmalloc is a lock-free memory allocator aiming to be an
efficient high performance replacement for the standard
"libc" memory allocator in concurrent applications.
Top of Page
Visualization

Research perspectives:
Exploit visual ways to enhance capabilities in
- distributed algorithms understanding and analysis
- human-computer-interaction by means of special environments for information visualization
- perception of abstract concepts such as causal relations and tree hierarchies.
|
Example applications:
- Visualization and debugging environments for parallel and distributed software
- Computer supported cooperative work
- Simulation and Game applications
- Workspace management
- Educational environments
- Steering and monitoring of distributed systems
|
Links to our projects/results
-
TrustNeighborhoods:
TrustNeighborhoods is a security trust visualization aimed at
novice and intermediate users of a distributed file sharing
system. Building on the idea of ``circles of relationships''
as a model for computer usage proposed by Shneiderman, the
technique uses the metaphor of a city to intuitively
represent trust as a simple geographic relation.
-
PMorph:
An interaction technique for projection matrix manipulation
that reduces inter-object occlusion in 3D environments
without modifying the geometrical state of the objects
themselves. Provides smooth on-demand morphing between
parallel and perspective projection modes, allowing the user
to quickly and easily adapt the view to avoid inter-object
occlusion.
-
BalloonProbe:
A space distortion interaction technique which, on the user's
command, inflates a spherical force field that repels objects
around the 3D cursor, separating occluding objects. Inflation
and deflation is performed through smooth animation, ghosted
traces showing the displacement of each repelled object.
-
 Lydian:
Lydian is an extensible simulation and visualization
environment for distributed algorithms. By creating own
experiments, users can perceive a whole execution by choosing
from several 2D and 3D animations illuminating various
aspects of each protocol. Lydian is already being used in
several courses internationally.
Lydian:
Lydian is an extensible simulation and visualization
environment for distributed algorithms. By creating own
experiments, users can perceive a whole execution by choosing
from several 2D and 3D animations illuminating various
aspects of each protocol. Lydian is already being used in
several courses internationally.
-
 CausalViz:
This project deals with the development of novel
visualization techniques for causal relations based on
animation, colors and patterns to provide an alternate
graphical representation of causality in a system that
facilitates quick overview.
CausalViz:
This project deals with the development of novel
visualization techniques for causal relations based on
animation, colors and patterns to provide an alternate
graphical representation of causality in a system that
facilitates quick overview.
-
CiteWiz:
CiteWiz is an open platform for the visualization of
citation networks. The tool has a central citation database
that is accessible to a number of different visualizations
that present the data in different ways. Current
visualizations include an adaptation of the Growing Polygons
technique, as well as a novel static timeline visualization
that highlights the influence and chronology of authors and
papers in the database.
Top of Page
|
