Every week there will be exercises you can answer. They are completely optional, but are meant to help you master the course. You can ask for help with them at the lab sessions.
There are answers to most of the exercises here. But please try the exercises before looking at the answers!
Week 1
Introduction
-
Implement dynamic arrays in your favourite programming language.
-
Implement a "guess-the-number" game using binary search: I think of a number between 1 and 10000, your program guesses a number and I reply whether my number is higher or lower. Your program makes a new guess and so on until it guesses the right number. Then extend your program so that I can pick any positive number, not just ones up to 10000.
-
Write a method that reverses an array.
-
Write a method that interleaves two strings: it should take one character from the first string, then one from the second string, another from the first string and so on. Once one string has no characters left it should carry on with the other string. For example, interleaving the strings "anna" and "patrik" should give the result "apnantarik" (or "paantnraik"). Use s.length() to find the length of a string and s.charAt(i) to find the character at index i.
-
Do exercise 5.9 ("For the binary search routine…") from Weiss. (International edition: 5.2.)
Complexity
-
Arrange the following functions in order of complexity: n4, log n, n log n, 4n, 3n3, 5n2 + n.
-
Assume that you have an algorithm that takes 2n steps and each step takes a microsecond. What is the largest problem size you can solve before the death of the Sun? Assume that the Sun will die in 5 billion years.
-
Here are the growth rates of several algorithms. Which will run in a reasonable amount of time when n = 50?
-
10 × 2n
-
10000 × log2 n
-
100000 × n
-
10 × n!
-
-
Write the following functions in big-O notation:
-
34x + x2
-
1x + 2x + 3x + 4x + 5x + 6x + 7x
-
104000x + 0.005 x2 + 103/x3
-
10 log2 x + 2 log10 x
-
2x + 10x
-
(x–2) (x–1) x
-
-
What is the complexity of adding a single element to an ArrayList? What is the complexity of adding n elements?
-
Suppose we want to be able to delete elements from a dynamic array. If we want to delete an arbitrary element, what is the complexity? What if we are allowed to change the order of the elements in the array?
-
Do exercises 5.16 (For 1,000 items…), 5.21 (Occasionally, multiplying the sizes…) and 5.23 (Unlucky Joe…) from Weiss. (International edition: 5.15, 5.30, 5.27.)
-
It’s important to represent your data in the right way. Suppose you have an array of n elements, then you can check if it has duplicate elements in O(n2) time, by looping over every pair of elements. But if the array is sorted, you can do it in O(n) time. How?
Week 2
Sorting
-
Check out the following visualisations of sorting algorithms:
-
Sorting out sorting, an 80s-tastic video comparing different sorting algorithms
-
What complexities do the following operations have?
-
Finding an element in an unsorted array of n elements
-
Finding an element in a sorted array of n elements
-
Adding an element to an unsorted array of n elements
-
Adding an element to a sorted array of n elements (the resulting array should also be sorted)
The moral is that all data structures make tradeoffs—choosing a different representation will make some operations faster but others slower.
-
-
Sort the sequence 4 6 8 2 9 5 1 7 3 by hand with:
-
Insertion sort
-
Selection sort
-
Quicksort (picking the first element as the pivot)
-
Quicksort (using the median-of-three pivot)
-
Mergesort
-
-
A sorting algorithm is stable if equal elements always remain in the same relative order before and after sorting. Which of our sorting algorithms are stable? Why?
-
Suppose you have an array of booleans of size n. Give an O(n) algorithm that sorts the array so that all false elements come before all true elements. Your algorithm should use O(1) extra memory.
-
Write a method or function that removes all duplicate elements from a Java array or Haskell list in O(n log n) time. Hint: sort the array first (you may use the sorting function from the standard library).
-
Do exercise 8.8 (worst-case input for quicksort) from the book. (International edition: 8.9.)
-
The implementation of mergesort that we saw in the lecture traverses the array three times to split in half (once to call length, once to call take and once to call drop). Can you define a function splitInHalf :: [a] → ([a], [a]) that splits a list in two equal pieces after traversing it only once? Hint: your function will probably split the list into the elements with odd indexes and the elements with even indexes (e.g. splitInHalf [1,4,6,7,2] = ([1,6,2], [4,7])).
Week 3
Quicksort
Do the exercises from last week that mention quicksort :)
Complexity of recursive functions
-
Write a method with the following signature
void printSubsets(int[] array)
that prints out all subsets of the input array. Use recursion. Alternatively, write a Haskell function
subsets :: [a] -> [[a]]
that returns all subsets of a list. What is its complexity? Start by writing a recurrence relation. Assume that printing out a single subset is O(1).
-
Do exercises 7.17, 7.19 (solving recurrence relations) from the book. (International edition: 7.19, 7.20.)
Week 4
Stacks and queues
-
Give an algorithm that removes all comments from a program. Assume that comments are written as (* ... \*) and can be nested (i.e. (* a comment with (* another comment *) inside *)). Write your algorithm in natural language or pseudocode if you like. What is the complexity of your algorithm?
-
Write a program that reads a postfix expression and evaluates it.
-
Implement a bounded queue class using circular arrays as in the lecture. Then build an unbounded queue class using the size-doubling trick. The implementation of your unbounded queue should use a bounded queue.
-
You might think that we can easily adapt the Haskell queue implementation to a deque. But there is a trap. Imagine that we have a queue of four elements:
Queue{front = [], rear = [4,3,2,1]}
Removing an element from the front, we move rear to front and get:
Queue{front = [2,3,4], rear = []}
If we now remove an element from the back, we will move front to rear again and get:
Queue{front = [], rear = [3,2]}
By alternating removing elements from the front and the back, we get a sort of "ping-pong" effect where every time we remove an element we reverse the list of elements. Removal will then have O(n) complexity instead of O(1).
There is a standard trick to fix this. When removing an element from the front of the queue and front is empty, instead of taking the whole of the rear list and reversing it, we only take half of it. We reverse that half and move it to front, while the other half stays in rear. In our example above, after removing the first element from the queue, we would get:
Queue{front = [2], rear = [4,3]}
We use the same trick when removing an element from the back of the queue and rear is empty. Using this trick, implement a deque in Haskell where all operations have O(1) complexity.
-
In the queue implementation in the lecture we record the size of the queue in a field. You might think that we don’t need to do this: the size is simply the number of elements between front and rear, i.e., (rear - front + 1) % capacity. Instead of storing the size, we could compute it using this formula whenever we need to know it. But this doesn’t work. Why?
Week 5
Binary heaps
-
A max heap is a heap which operates on the maximum element instead of the minimum. That is, it has operations findMax and deleteMax instead of findMin and deleteMin.
-
Suppose you have an implementation of a min heap. How would you change it into a max heap?
-
Java provides a class PriorityQueue<E> that implements a min heap. Define a class that uses PriorityQueue<E> to implement a max heap. Hint: you will need to use a custom Comparator when you initialise the priority queue.
-
-
Insert the following elements in sequence into an empty heap: 6, 8, 4, 7, 2, 3, 9, 1, 5. Draw both the tree and array representations of the heap. Then illustrate building a heap from the same data.
-
Is heapsort stable? (See exercise 4 from the sorting exercises for what stable means.)
-
(Harder) Remember from the lectures that a binary tree is complete if all its levels are completely full, except for the bottom level which is filled from left to right. The following diagram illustrates a complete binary tree.
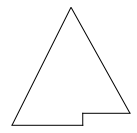
Write a O(n) function that checks if a binary tree is complete or not.
Hint: you will need a helper function that calculates these three pieces of information at once:
-
Whether the tree is complete or not.
-
The height of the tree.
-
Whether the bottom level of the tree is full.
-
Leftist heaps
-
Implement leftist heaps in Haskell or your favourite programming language.
-
As mentioned in the lectures, we can use a priority queue to implement sorting as follows: start with an empty priority queue, add all elements of the input list in turn, and then repeatedly find and remove the smallest element. Perform this sorting algorithm by hand on the list [3,1,4,2,5] using a leftist heap.
Week 6
Binary trees
-
In what order will the elements of the following tree be traversed in a preorder traversal, an inorder traversal, a postorder traversal, and a level-order traversal?
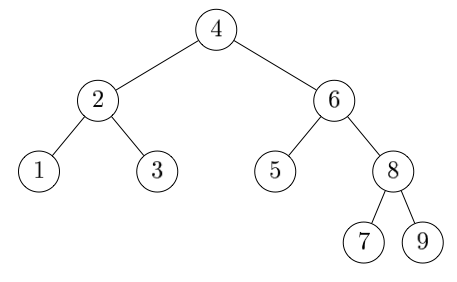
-
Is the following statement true or false? Why?
Inserting a set of objects into a binary search tree, you get the same tree regardless of what order you insert the objects in. -
How many nulls are there in a binary tree of n nodes? Why?
Balanced binary search trees
-
Insert the values 2,1,4,5,9,3,6,7 into:
-
A binary search tree
-
An AVL tree
-
A red-black tree
-
A 2-3 tree
-
-
Insert the values 1,2,3,4,5,6,7,8 into:
-
A binary search tree
-
An AVL tree
-
A red-black tree
-
A 2-3 tree
-
-
We treated 2-3 trees quite informally. Write down the search and insertion algorithms for a 2-3 tree in pseudocode.
-
Remember from the lectures that a red-black tree is a clever encoding of a 2-3-4 tree using a binary tree. Compare the operations on red-black trees and 2-3-4 trees and work out the correspondence for yourself. You may want to check, for example, what operation in a red-black tree corresponds to splitting. Another informative thing to check: how does the red-black invariant correspond to the 2-3-4 invariant of "the tree is perfectly balanced"?
Also, the insertion algorithm that we saw for 2-3-4 trees corresponds to bottom-up insertion on red-black trees. Can you work out how top-down insertion would work in a 2-3-4 tree?
Week 7
Hash tables
-
What are the advantages and disadvantages of hash tables compared to binary search trees?
-
In linear probing, we have to use lazy deletion to remove elements from the hash table: instead of clearing the array index where the element is stored, we have to mark it as deleted (see the slides). Show that this is necessary, by finding an example that goes wrong if we delete an item naively.
Instead of using lazy deletion, you could instead find the element you want to delete, find the last element in the deleted element’s cluster, and then move that element so that it overwrites the deleted element. The idea is that this keeps the cluster in one piece, which avoids the problem with naive deletion. However, it doesn’t work. Find an example where it goes wrong.
Tail recursion
-
-
Define a Haskell function member :: Eq a ⇒ a → [a] → Bool that tests whether a given element is a member of a list. Your function should be tail-recursive.
-
Now imagine a Java type corresponding to the Haskell list type: class List<E> { E value; List<E> next; }. Translate the function from part a into a tail-recursive Java method boolean member(E value, List<E> list). Do this with as little thought as possible: just mechanically translate the Haskell into Java.
-
Now make your Java method iterative (a loop), using the technique from the lecture.
-
-
Imagine that we want to search for a value in a binary tree that is not a binary search tree (i.e. the elements can appear in any order). The tree is represented by a class Tree<E> as follows:
class Tree<E> { E value; Tree<E> left; right; int height; // height of this node }
Note that each tree node contains a height field giving the height of the node.
-
Write a method boolean member(E value, Tree<E> tree) that searches for a value in the tree. What is its space (memory) complexity? Remember to include the call stack in your calculation!
-
Alter the method so that it uses O(log n) space. Hint: look at the quicksort example. Start by making a method that would use O(log n) space in a language with tail call optimisation, then transform the tail recursion to a loop.
-