| Testing, Debugging, and Verification | TDA567/DIT082, LP2, HT2018 |
Exercises Week 3 | |
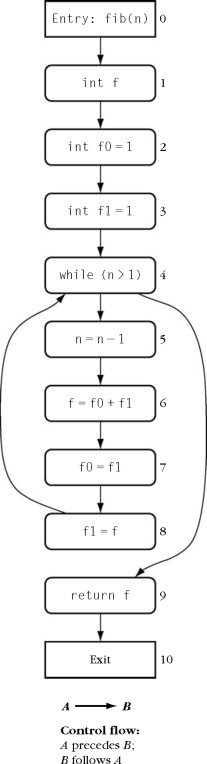
Tracking causes and effectsThe following method intends to compute the n-th Fibonacci number, but contains a bug for the first two numbers (Java source). 0: static int fib(int n) { 1: int f = 0; 2: int f0 = 1; 3: int f1 = 1; 4: while (n > 1) { 5: n--; 6: f = f0 +f1; 7: f0 = f1; 8: f1 = f; } 9: return f; }
2. Ordinary debuggingThe Merge sort is one of the most common algorithms used to sort arrays. The class MergeSort implements this algorithm. However, there is a bug in the implementation of the method sort. Debug the previous implementation using the debugging options of your favourite IDE (e.g. eclipse), in order to find the error.
The bug is in the manner the indexes are handle when performing the recursive calls, i.e. one value in the array is missed every time. Replacing sort(array, from, m - 1) by, for instace, sort(array, from, m) would fix this method.
Input minimisationIn this exercise we take a look at one particular algorithm for minimising a (failing) test input: the ddmin algorithm (published here). Download the following archive: DDMin.zip
In eclipse, import the project by choosing File -> Import ... -> Existing Project into Workspace. Your task is the following:
If you have AspectJ installed, you can instead download this version which uses aspects for logging, to avoid cluttering of the code: DDMinAspects.zip
A short annotation on the debugging output:
ddmin 2 - [a, , d, e, b, u, g, g, i, n, g, , t, e, s, t]We started ddmin with chunk size 2. Thus, we split into two halves. The first test is when we removed the first chunk (half), and then the test when we removed the second chunk: test [i, n, g, , t, e, s, t] PASS test [a, , d, e, b, u, g, g] PASSBoth passed, so we are not that lucky that we can minimise the failing input a lot in one go. Instead, ddmin now tries to remove a shorter chunk, by dividing the input into 4 parts (doubling the current size). ddmin 4 - [a, , d, e, b, u, g, g, i, n, g, , t, e, s, t]We now remove the first chunk, that is 1/4 of the whole input, [a, , d, e]: test [b, u, g, g, i, n, g, , t, e, s, t] FAILNow ddmin was succesful, and 'already did its job': it reduced the original input and still found a failing test case. However, the goal is to minimise as much as possible so we go further on this failed input. Having removed one chunk, we also continue on a chunk size of one shorter (4-1=3). We thus get the three chunks [b, u, g, g], [i, n, g, ] and [t, e, s, t]: ddmin 3 - [b, u, g, g, i, n, g, , t, e, s, t] test [i, n, g, , t, e, s, t] PASS test [b, u, g, g, t, e, s, t] PASS test [b, u, g, g, i, n, g, ] FAILAnother chunk can be removed succesfully! Again, we continue on that smaller input and continue on chunk size (3-1=2): ddmin 2 - [b, u, g, g, i, n, g, ] test [i, n, g, ] PASS test [b, u, g, g] PASSBoth succeeded, so we again double the number of chunks, reducing the size of each chunk and making it more possible that the remaining input still fails: ddmin 4 - [b, u, g, g, i, n, g, ] test [g, g, i, n, g, ] FAILThe rest of the algorithm goes on similarly: ddmin 3 - [g, g, i, n, g, ] test [i, n, g, ] PASS test [g, g, g, ] FAIL ddmin 2 - [g, g, g, ] test [g, ] PASS test [g, g] PASS ddmin 4 - [g, g, g, ] test [g, g, ] PASS test [g, g, ] PASS test [g, g, ] PASS test [g, g, g] FAIL ddmin 3 - [g, g, g] test [g, g] PASS test [g, g] PASS test [g, g] PASSAt this point the number of chunks is 3, but that is also the length of the array. So increasing the number of chunks is not possible, since we cannot make chunks that small (the smallest ones contain at least one element, otherwise we don't make the input shorter). Therefore the algorithm concludes: Minimalised version of 'a debugging test' is 'ggg'.However, due to our 'greedyness', we first dropped the first four elements of the array [a, , d, e, b, u, g, g, i, n, g, , t, e, s, t], thereby removing the possibility of arriving at minimal input [e,e]. This demonstrates that the algorithm gets a local optimal, but not a global optimal. When was this bug introduced?In this scenario, we will pretend that we are working on a little software project, implementing a merge sort function. Like in any project, we work with a version control system. Download the archive: bisect.zip Unzip this archive on your computer. It contains a git repository. The merge function has seen many improvements, and has been constantly tested. Everything seems to be working well. However, one day someone reports a bug to your project, observing that the following list is not sorted correctly:
{3, 6, 8, 7, 1, 5, 2}
Since we never tested this input, the corresponding bug might have been introduced in any of the earlier versions of the merge function. We will use our version-controlled system to find out where the bug originated.
Additional quiz-questions from the exercise session:1) x = 4; 2) if (y == 2) 3) x = 7; 4) z = x;1. On which lines is line 4 data-dependent? 1) x = 4; 2) if (y == 2) 3) x = 7; 4) else 5) x = 5; 6) z = x;2. On which lines is line 6 data-dependent? 1) if (y == 4) 2) x = 3; 3) x = x + 1;3. On which lines is line 2 control-dependent? 4. On which lines is line 3 control-dependent? 5. On which lines is line 3 backward-dependent? 6. Given a test on arrays of numbers, that fails if we have two consequetive values. We are given the failing input [1,2,2,3]. What is the first smaller array on which ddmin([1,2,2,3], 2) performs the test that returns fail? (note: we are not asking for the final result of ddmin, although that is also a good exercise). Bugfinding toolsBelow you can find a list of several tools which you can use to debug your (Java) programs.
| |
| Home | Course | Schedule | Exam | Exercises | Labs | Evaluation | Tools | Links | Srinivas Pinisetty, Nov 9, 2018 |
{kind=link}