Workers
What would it happen if you use pmap with a list of 1.000.000.000 elements?
Sometimes, it is necessary to impose some resource limits
Parallel processes, open files, etc.
Gives stability to the system
The workers model is designed for that goal
We have tasks (computations) divided among a number of workers
- Workers are simple processes
Workers can be active or passive.
- An active worker is a process already performing computations related to a task(s),
- A passive worker is waiting to be assigned to a task(s).
There is a server, called a pool, that keeps track of the tasks to be performed and has a fix number of workers willing to take those tasks.
Server behavior
The initial state of the server is a queue of tasks and a list of passive workers
A worker can take more than a single task
An active worker becomes passive after finishing with the assigned task(s)
A passive worker becomes active when being assigned a task(s).
The server finishes execution when the queue of tasks is empty and there are no active workers
The server waits for a worker to return a result when the queue is empty or there are no more passive workers
When the task queue is not empty, the server gets a passive worker and assign some chunk of tasks to perform, i.e., the worker is now active
Implementation of workers
worker(Compute) ->
spawn (fun () -> worker_body(Compute) end ).
worker_body(Compute) ->
receive {Pid, Tasks} ->
Result = Compute(Tasks),
Pid ! {self(), Result},
worker_body(Compute)
end.
Implementation of the server
-record(st, { tasks, aworkers, pworkers, get, combine } ). %% Done work_load(#st{tasks = [], aworkers = []}, Results) -> Results; %% There are tasks to give to a passive worker work_load(St = #st{tasks = [Task | Tasks], pworkers = [PWorker | PWorkers], aworkers = AWorkers, get = Get} , Results) -> {Chunk, TTasks} = Get([Task | Tasks]), PWorker ! {self(), Chunk}, work_load(St#st{tasks = TTasks, pworkers = PWorkers, aworkers = [PWorker | AWorkers] } , Results) ; %% No more passive workers or empty tasks, then %% wait for results work_load(St = #st{pworkers = PWorkers, aworkers = AWorkers, combine = Combine } , Results) -> receive {Worker, Result} -> work_load (St#st{ pworkers = [Worker | PWorkers], aworkers = lists:delete(Worker, AWorkers) } , Combine(Result, Results)) end.
Function pmap using workers
Limit the resources to two workers only
Tasks are the elements in the list, i.e.,
[X1,X2,X3]has three tasks.The computation of the worker is just to apply
Fto its tasks, e.g.,F(X).Getting a task is simply taking the first task
get_pmap([X | Xs]) -> {X, Xs}.Combine a new result is simply to add it to the lists of computed results
combine_pmap(R, Rs) -> [R | Rs].
The initial result is the empty list
pmapwith two workerspmap(F, Xs) -> W1 = worker(F), W2 = worker(F), start(Xs, [W1, W2], fun get_pmap/1, fun combine_pmap/2, []).
On lock based programming
Lock-based programming is difficult
There are many potential problems:
Deadlock
Starvation
Non-compositionality
Is there some way to eliminate at least some of these problems?
Lock-based programming does not compose
Suppose you have two thread safe buffers and you want to atomically take an element from one of them and put it in the other
class Buffer<Elem> { Elem get() {} ; void put(Elem) {} ; }
A not so nice solution
Expose the the locks of the buffers
class Buffer<Elem> { void aquireLock(); void releaseLock(); Elem get(); void put(Elem); }Lock both buffers before moving the element
class TwoBuffer<Elem> { private Buffer<Elem> b1 ; private Buffer<Elem> b2 ; void copy_elem() { b1.aquireLock() ; b2.aquireLock() ; b2.put(b1.get()) ; b2.releaseLock() ; b1.releaseLock() ; } }It reduces opportunities for concurrency
It breaks abstraction!
What is you need to involved 3 buffers?
The number of locks grows as we compose algorithms
Increases the risk of programming errors
Lock-based synchronization can be seen as pessimistic concurrency: ”We always assume that we need mutual exclusion”
Another option would be optimistic concurrency
- Assume we have mutual exclusion
- Perform our critical section
- Check if everything was OK
- Revert our actions if it was not (rollback/retry)
- Otherwise proceed
Software Transactional Memories (STM)
A concept to allow easy lock-free programming and optimistic concurrency
Although the programming model is lock-free implementations uses locks
- Hardware or software level
- Programmer does not need to know about it!
Transactions: standard database concept
A group of operations should execute atomically,
Or not at all
One possible implementation of transactions
When writing to variables, do not actually modify them, instead the system keeps a log over all the reads and writes that are made
When the transaction is done the system checks that the read variables still have the same value as in the beginning of the transaction
If that is the case, make the changes permanent (known as commit)
Otherwise, rerun the transaction (known as rollback or retry)
To detect if a variable has changed, we assume a version number for each variable in the transaction
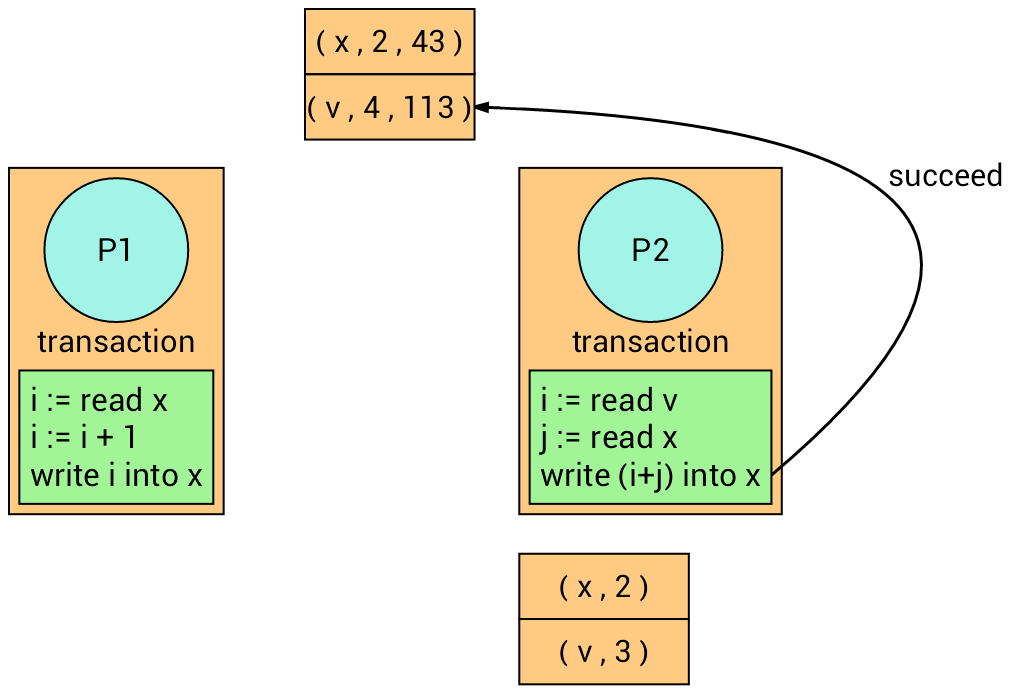
Example
We have two processes with two different transactions.
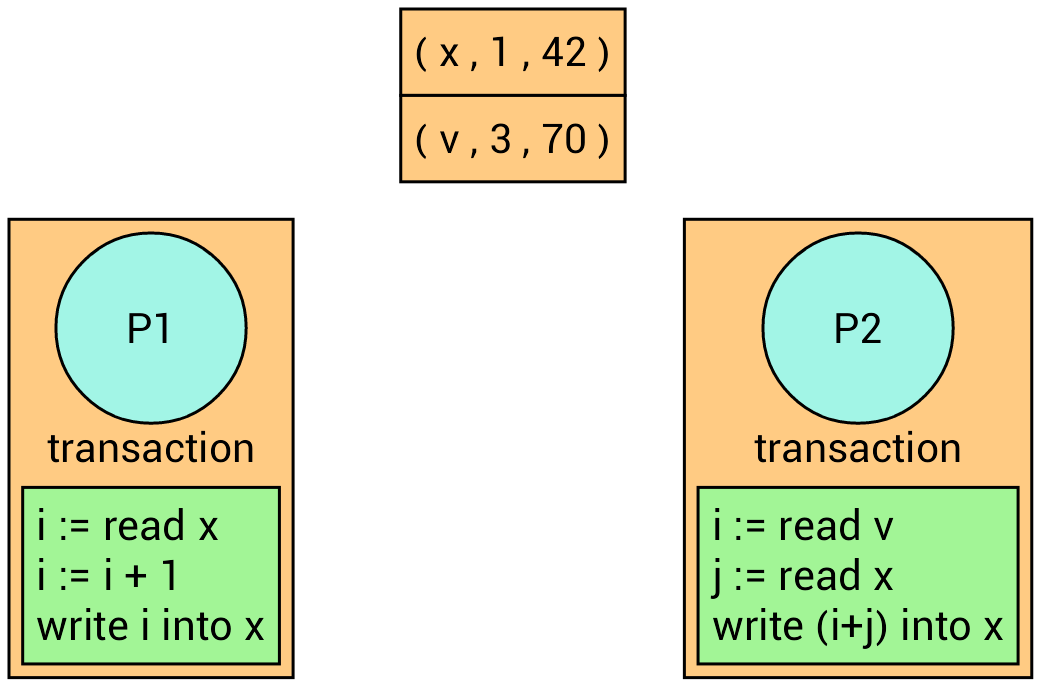
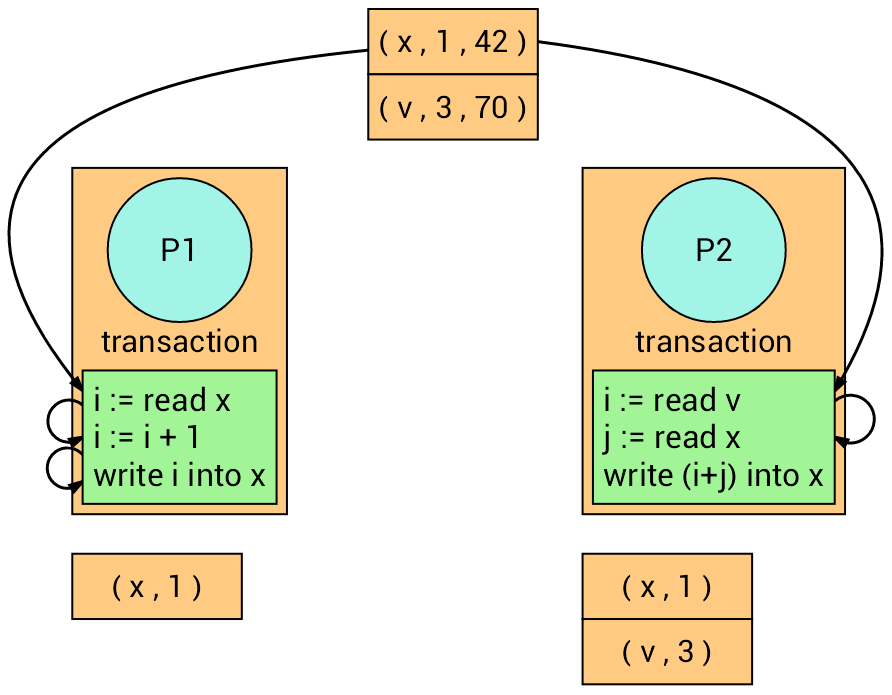
Now, both transactions read their corresponding variables. Each transaction recalls the version number of the read variables.
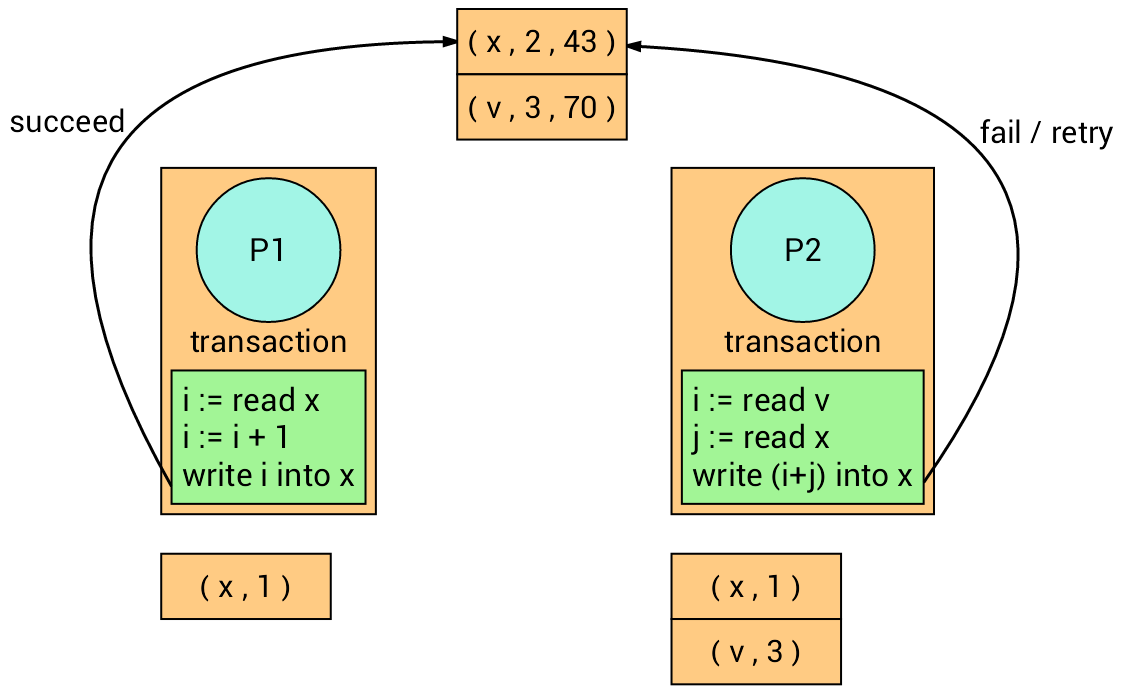
The transaction on the left firstly writes into variable x, and the
transaction on the right follows but it fails (Why?) and retry.
The transaction on the right retries.
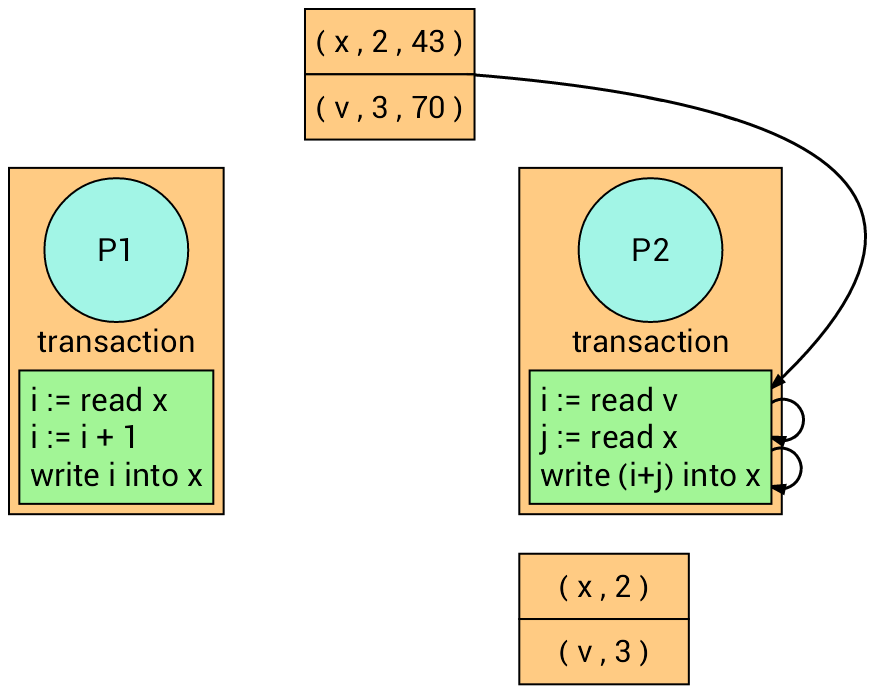
At the time of writing, it succeeds (Why?).
Benefits of transactions:
Many processes can be in the critical section at the same time
More parallelism
They only need to rerun if there is an actual runtime conflict
Deadlocks cannot occur
Easy to compose
Drawbacks of transactions:
Cannot guarantee fairness
- A large transaction can be starved by many small ones
All the book keeping can be expensive
STM are still a subject of reseach!
STM implementations
Software Transactional Memory can be used in various ways:
As a library
As a language construct
Libraries
Language support
- Haskell, Clojure, and Perl 6.
What about Erlang?
- We will implement it as a library! (inspired by this post )
STM in Erlang
Create a server that keeps track of transactional variables and its versions (transactional memory store)
In a transaction, a variable is of the shape
{Name, Version, Value}Interface
Functions
readandwriteare used to locally read and write a variable, respectivelyFunction
pullandpushare used to fetch and commit variables from and to the store, respectively.
%% new(Tm) -> ok %% create the transaction memory store (Tm) new(Tm) -> genserver:start(Tm, dict:new(), fun loop/2). %% add(Tm, Name) -> Var %% add a uninitialized variable to the Tm store add(Tm, Name) -> genserver:request(Tm, {add, Name, void}). %% add(Tm, Name, Init) -> Var %% add a initialized variable add(Tm, Name, Init) -> genserver:request(Tm, {add, Name, Init}). %% read(Var) -> Value %% return the value of a variable read({_Name, _Version, Value}) -> Value. %% write(Var, Value) -> ok %% write Value into Var write({Name, Version, _Value}, NewValue) -> {Name, Version, NewValue}. %% pull(Tm, Name) -> Var %% lookup variable Name in the Tm store pull(Tm, Name) -> genserver:request(Tm, {pull, Name}). %% push(Tm, Var) -> Bool %% update variable Var in the TM store push(Tm, Var) -> genserver:request(Tm, {push, Var}).Transactional memory store
loop(Vars, {add, Name, Init}) ->
case dict:find(Name, Vars) of
{ok, _} -> {ok, Vars} ;
error -> {ok, dict:store(Name, {0,Init}, Vars)}
end ;
loop(Vars, {pull, Name}) ->
case dict:find(Name, Vars) of
{ok, {Ver, Value}} -> {{Name, Ver, Value}, Vars} ;
_ -> {error, Vars}
end ;
loop(Vars, {push, Name, {Name, Ver, Value}}) ->
{VerTM, _} = dict:fetch(Name, Vars),
case Ver of
VerTM -> NewVars = dict:store(Name, {Ver+1, Value},
Vars),
{true, NewVars} ;
_ -> {false, Vars}
end.
- To increase performance,
pullandpushcould fetch and commit several variables at once (check this post by Joe Armstrong)
Composing transactions
Composing transactions is embarrassingly simple
Transaction to get an element from a buffer
get_buff(Tm, Name) -> Buff = pull(Tm, Name), [X | Xs] = read(Buff), NewBuff = write(Buff, Xs), push(Tm, Name, NewBuff), X.
Transaction to remove the first element of a buffer
put_buff(Tm, Name, X) -> Buff = pull(Tm, Name), Xs = read(Buff), NewBuff = write(Buff, Xs ++ [X]), push(Tm, Name, NewBuff).Transaction to get an element from one buffer into the other one
get_put_buff(Tm, Name1, Name2) -> Elem = get_buff(Tm, Name1), put_buff(Tm, Name2, Elem).Simple, right? Is it completely atomic? How could you fix it?
Adding a function
atomic(Function, [Args])which differs all the pushes until the end (need to modifypush)Homework to implement it! It is fun!
stm_get_put_buff(Tm, Name1, Name2) = atomic(fun get_put_buff/3, [Tm, Name1, Name2]).
Side-effects
Side effects such as I/O don't mix very well with transactional memory
Programs raise a runtime exception if I/O is performed during a transaction
Issues like these make it difficult to implement and program with transactional memory in most languages (Why? Rollback!)