Inconvenient truth(s)
- Moore's Law
- Coined in 1965 by Gordon Moore from Intel
- Chip complexity increases by a factor of 2 every year
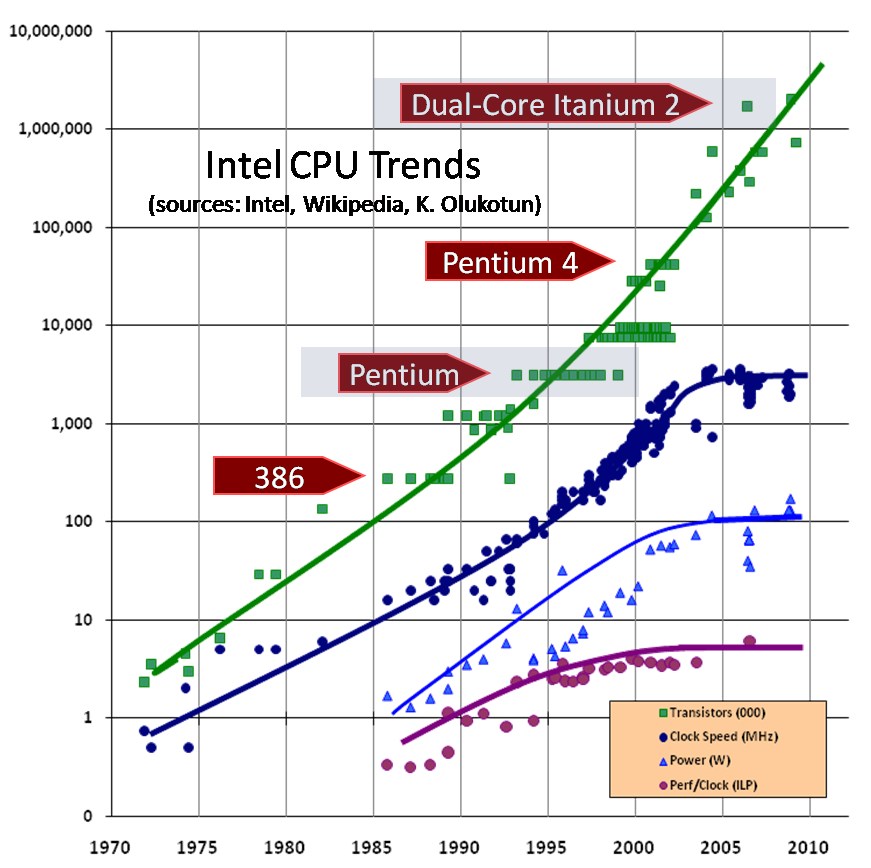
State-of-the-art processors are clocked at 4 GHz
- Light travels 7.5 cm every clock tick
- Not possible to clock the whole large system using the same clock
- Events that happen in different parts of the system close in time are simultaneous
Back to the 80s
- Intel's 80386 was released in 1986
- Initial clock rate was 12 MHz (1 tick every 83 ns)
- RAM latency: 70 ns
- No cache (cache added with 33 MHz version)
Intel Skylake (2015) die

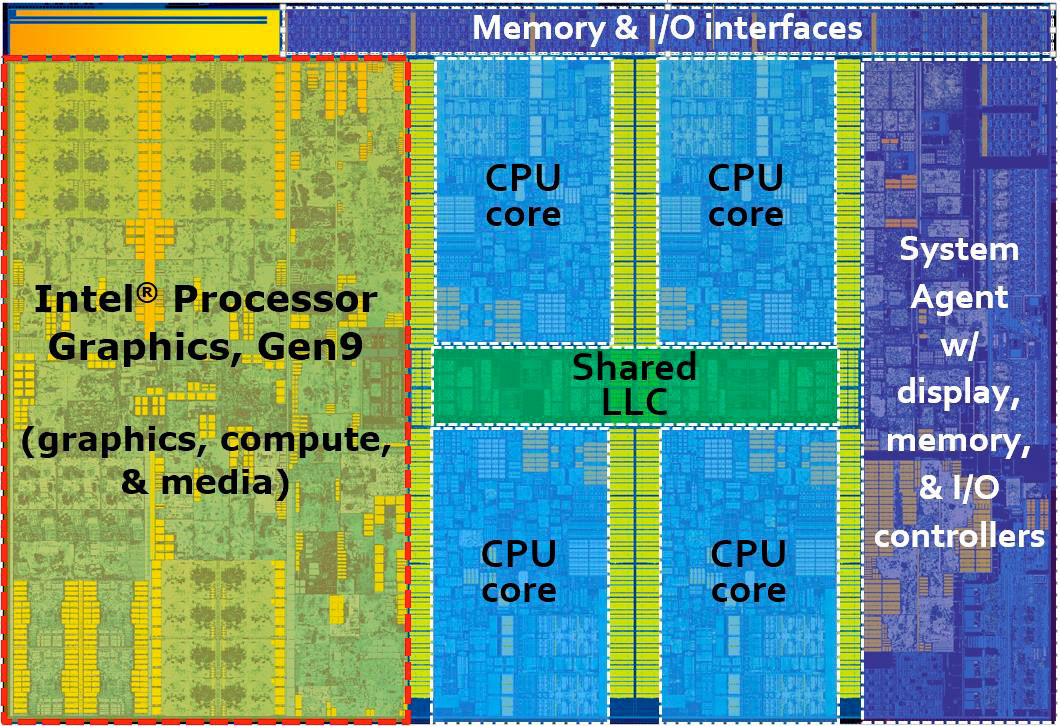

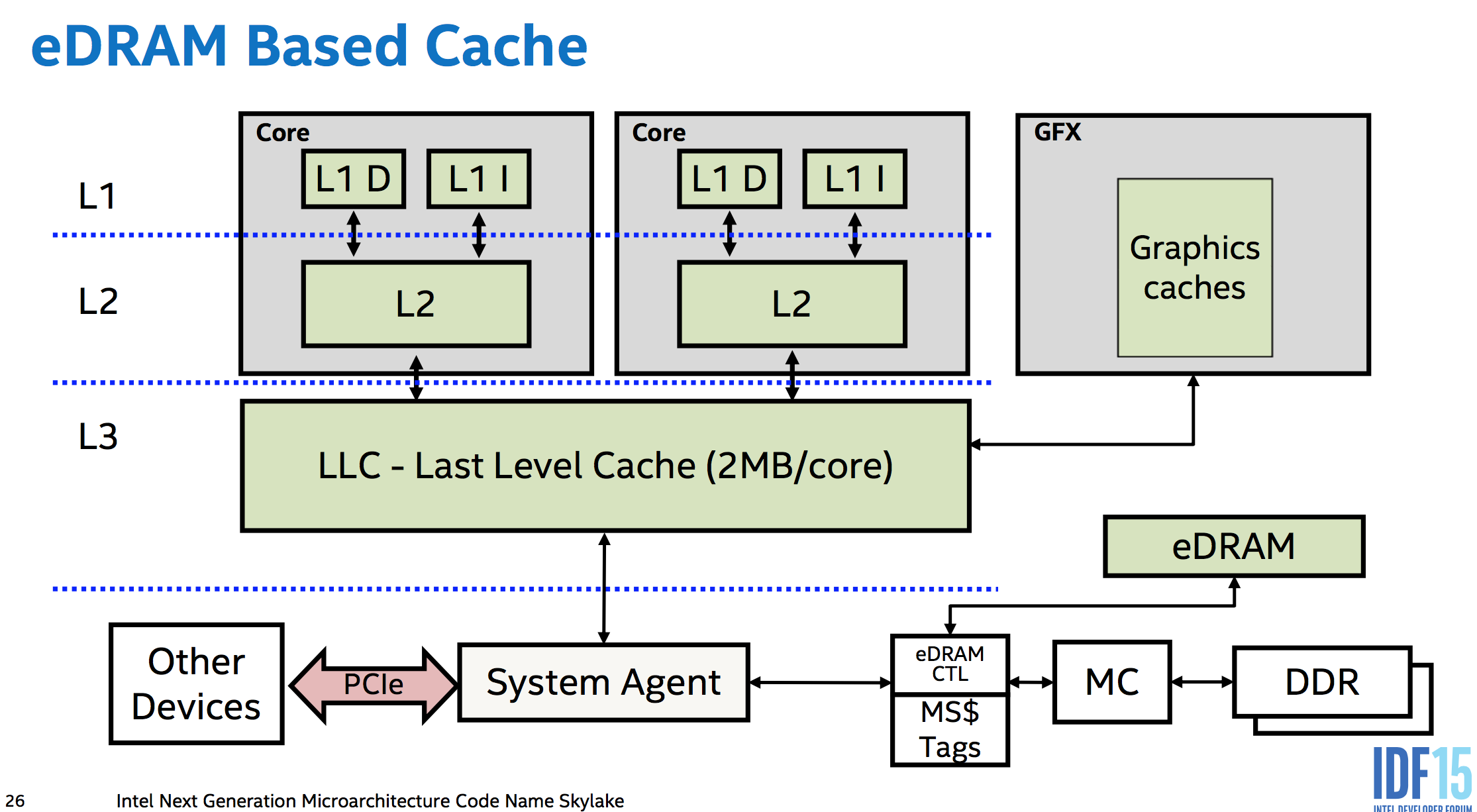
Intel Skylake (2015)
- Max ca. 4 GHz
- Cache (64 B/line)
- 32+32 KB L1 cache
- 2056 KB L2 cache
- 8 MB L3 cache (shared by 2 cores)
- Latencies
- L1: 4/5 cycles
- L2: 12 cycles
- L3: 42 cycles (if the same core)
- RAM: 42 cycles + 51 ns
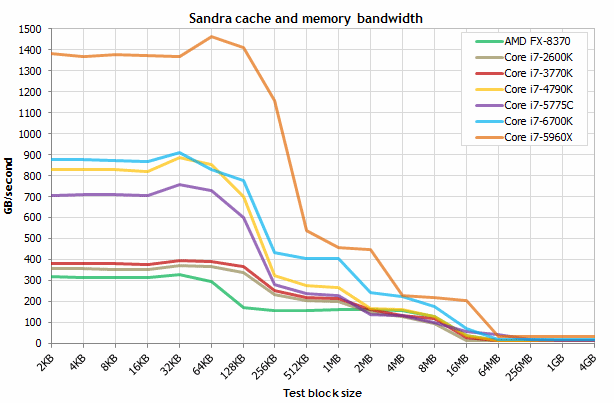
- Bandwidth
- L1, L2: probably maxed
- L3: ~200 GB/s
- RAM: ~30 GB/s (one benchmark)
In the 80s
- Computation was expensive
- i386 32-bit division: up to 43 clock cycles
- Transfer from memory was cheap
- i386: 3-4 cycles
- Computation was expensive
Now
- Computation is cheap
- Skylake 32-bit division: 26 cycles (throughput: every 6 cycles)
- Transfer from memory is expensive
- Skylake: about 246 cycles
- Computation is cheap
Caches and I/O take most od the die area
- Communication takes most of the energy
- 80s: Instruction saved is instruction earned
- Now: Memory access saved is memory access earned
- It all gets worse when different cores are competing for the same memory
Back-of-the-envelope calculations
It's difficult to predict the exact performance of individual instructions
Memory latency is hidden by caches, so it's also difficult to predict
Cache/memory bandwidth can be predicted more easily if you know the working set of your computation
You can't tell how fast your code will go, but you can tell how fast it won't go:)
You probably want to think about other I/O bandwidth (network, disk, etc.)
How to tune your application
Concurrent/parallel code will often behave not in the way you expect
Use benchmarking: if you cannot measure something, it does not exist!
Unrolling all loops will make my program faster - are you sure? Do it only if you can demonstrate its usefulness using benchmarks
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3% - Donald Knuth
Concentrate on finding the bottlenecks - the critical 3% - they might be not where you think they are
Sawzall
Domain-specific language created to compute statistics based on large quantities of data at Google (2005)
Average job 100 GB
Although Sawzall is interpreted, that is rarely the limiting factor in its performance. Most Sawzall jobs do very little processing per record and are therefore I/O bound; for most of the rest, the CPU spends the majority of its time in various run-time operations such as parsing protocol buffers.
Last year Sawzall has been retired in favour of Go (compiled)
Parallelizing computations
Embarrasingly parallel problems
- MapReduce
Sequential dependencies
- Amdahl's law: speedup due parallelization is limited by critical paths in the dependency graph of the computation
int c = 0;
for(int i = 0; i < n; ++i) {
c += a[i];
}


int c = 0;
int[] tmp = new int[4];
pfor (int j = 0; j < 4; ++j) { // This is pseudocode
for(int i = 0; i < n; ++i) {
tmp[j] += a[i];
}
}
for (int i = 0; i < 4; ++i) { c += tmp[i];}
- Associative operation (
+) allows for easy parallelization

- The CBC block cipher mode cannot be parallelized

Parallelizing encryption requires choosing a different mode, such as CTR
Removing dependencies gives more benefits than just parallelizing opportunity
Multicore
Aspects
Applications to run faster if we have multicore CPUs
- Alternatively, several CPUs in a distributed setting
Is the code going to run faster just by having more cores?
No!
It might if it has lots of non-interferent processes and no sequential bottlenecks
Erlang uses all the cores on the SMP machine by default
Symmetric MultiProcessing
erl -smp +S N
The number
Nindicates how many schedulers (govern Erlang virtual machines)Useful to test how the program works on different amount of cores
Speeding up programs on a multicore CPU
General guidelines
Use lots of processes
- To keep cores busy!
Avoid side effects
- Their order might change in the parallel version
Avoid sequential bottlenecks
- If the algorithm is intrinsically sequential, then larger changes are needed
Write “small messages, big computations” code.
- If computations are very small, it might be bigger the cost of spawning and messaging among processes
Making code run in parallel
- Definition of
map
map(_, []) -> []; map(F, [H|T]) -> [F(H)|map(F, T)].
- Can the application for each element be done in parallel?
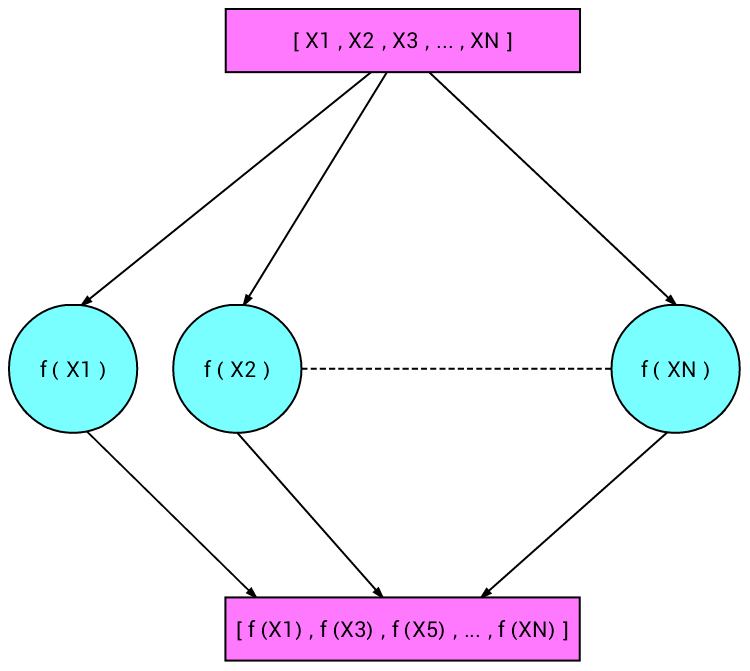
pmap(F, Xs) ->
S = self(),
Ref = make_ref(),
Pids = map(fun(X) -> spawn( fun() ->
S ! {self(), Ref, F(X)}
end )
end, Xs),
gather(Pids, Ref).
gather([Pid|T], Ref) ->
receive
{Pid, Ref, Ret} -> [Ret|gather(T, Ref)]
end ;
gather([], _) -> [].
map(F,L) =:= pmap(F,L)Order of elements?
Side-effects?
What if the list is very big and the computation
Fvery small?
Workers
What would it happen if you use pmap with a list of 1.000.000.000 elements?
When doing X, a question arises: how many threads should I spawn here?
- Too few: wasted parallelisation opportunity
- Too many: overloaded system
- Threads expensive
- Subcomputations may use significant resources (files, memory, network)
- You are willing to give up the control on what to run exactly when
The workers model is designed for that goal
Ideal: system-wide queue
- Application-wide/component-wide queues also useful
Workers example
We have tasks (computations) divided among a number of workers
- Workers are simple processes
Workers can be active or passive.
- An active worker is a process already performing computations related to a task(s),
- A passive worker is waiting to be assigned to a task(s).
There is a server, called a pool, that keeps track of the tasks to be performed and has a fix number of workers willing to take those tasks.
Server behavior
The initial state of the server is a queue of tasks and a list of passive workers
A worker can take more than a single task
An active worker becomes passive after finishing with the assigned task(s)
A passive worker becomes active when being assigned a task(s).
The server finishes execution when the queue of tasks is empty and there are no active workers
The server waits for a worker to return a result when the queue is empty or there are no more passive workers
When the task queue is not empty, the server gets a passive worker and assign some chunk of tasks to perform, i.e., the worker is now active
Implementation of workers
worker(Compute) ->
spawn (fun () -> worker_body(Compute) end ).
worker_body(Compute) ->
receive {Pid, Tasks} ->
Result = Compute(Tasks),
Pid ! {self(), Result},
worker_body(Compute)
end.
Implementation of the server
-record(st, { tasks, aworkers, pworkers, get, combine } ). %% Done work_load(#st{tasks = [], aworkers = []}, Results) -> Results; %% There are tasks to give to a passive worker work_load(St = #st{tasks = [Task | Tasks], pworkers = [PWorker | PWorkers], aworkers = AWorkers, get = Get} , Results) -> {Chunk, TTasks} = Get([Task | Tasks]), PWorker ! {self(), Chunk}, work_load(St#st{tasks = TTasks, pworkers = PWorkers, aworkers = [PWorker | AWorkers] } , Results) ; %% No more passive workers or empty tasks, then %% wait for results work_load(St = #st{pworkers = PWorkers, aworkers = AWorkers, combine = Combine } , Results) -> receive {Worker, Result} -> work_load (St#st{ pworkers = [Worker | PWorkers], aworkers = lists:delete(Worker, AWorkers) } , Combine(Result, Results)) end. start(Tasks, Workers, Get, Combine, InitialResult) -> St = #st{tasks = Tasks, pworkers = Workers, aworkers = [], get = Get, combine = Combine}, work_load(St, InitialResult).
Function pmap using workers
Limit the resources to two workers only
Tasks are the elements in the list, i.e.,
[X1,X2,X3]has three tasks.The computation of the worker is just to apply
Fto its tasks, e.g.,F(X).Getting a task is simply taking the first task
get_pmap([X | Xs]) -> {X, Xs}.Combine a new result is simply to add it to the lists of computed results
combine_pmap(R, Rs) -> [R | Rs].
The initial result is the empty list
pmapwith two workerspmap(F, Xs) -> W1 = worker(F), W2 = worker(F), start(Xs, [W1, W2], fun get_pmap/1, fun combine_pmap/2, []).
On lock based programming
Lock-based programming is difficult
There are many potential problems:
Deadlock
Starvation
Non-compositionality
Is there some way to eliminate at least some of these problems?
Lock-based programming does not compose
Suppose you have two thread safe buffers and you want to atomically take an element from one of them and put it in the other
class Buffer<Elem> { Elem get() {} ; void put(Elem) {} ; }
A not so nice solution
Expose the the locks of the buffers
class Buffer<Elem> { void aquireLock(); void releaseLock(); Elem get(); void put(Elem); }Lock both buffers before moving the element
class TwoBuffer<Elem> { private Buffer<Elem> b1 ; private Buffer<Elem> b2 ; void copy_elem() { b1.aquireLock() ; b2.aquireLock() ; b2.put(b1.get()) ; b2.releaseLock() ; b1.releaseLock() ; } }Alternatively: use one more lock that is locked in addition
Problems with lock granularity
- Too few locks: reduces opportunities for concurrency
- Too many locks: race conditions may occur
Deadlocks (however, we know how to avoid them)
It breaks abstraction!
What is you need to involved 3 buffers?
The number of locks grows as we compose algorithms
Increases the risk of programming errors
Solution: atomic blocks
What we want
class TwoBuffer<Elem> { void copy_elem() { atomic { b2.put(b1.get()) ; } } }We want blocks that are globally atomic (not only synchronized on a particular lock)
We don't want to 'lock the world' at every state modification
We will use a trick
do { int old = shared; int new = old + 1; } while (compare-and-swap(shared, old, new) != old);STM is like extending compare-and-swap to work on many variables a the same time
The loop will execute more than once only if there is a conflict between two threads
Lock-based synchronization can be seen as pessimistic concurrency: ”We always assume that we need mutual exclusion”
Another option would be optimistic concurrency
- Assume we have mutual exclusion
- Perform our critical section
- Check if everything was OK
- Revert our actions if it was not (rollback/retry)
- Otherwise proceed
Software Transactional Memories (STM)
A concept to allow easy lock-free programming and optimistic concurrency
Although the programming model is lock-free implementations uses locks
- Hardware or software level
- Programmer does not need to know about it!
Transactions: standard database concept
A group of operations should execute atomically,
Or not at all
One possible implementation of transactions
When writing to variables, do not actually modify them, instead the system keeps a log over all the reads and writes that are made
When the transaction is done the system checks that the read variables still have the same value as in the beginning of the transaction
If that is the case, make the changes permanent (known as commit)
Otherwise, rerun the transaction (known as rollback or retry)
To detect if a variable has changed, we assume a version number for each variable in the transaction
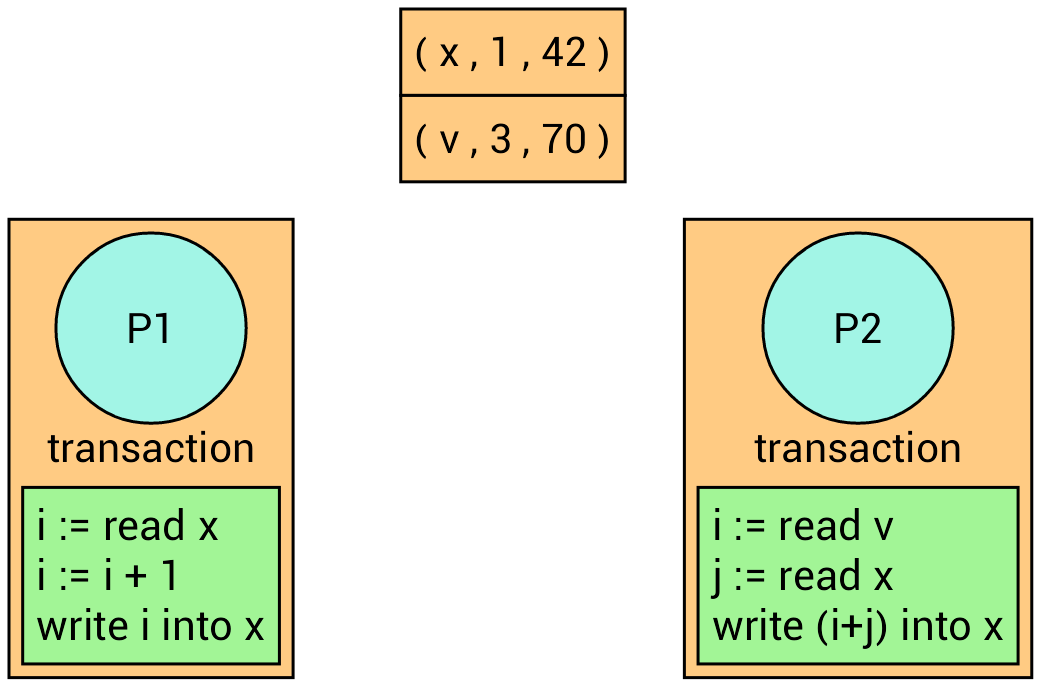
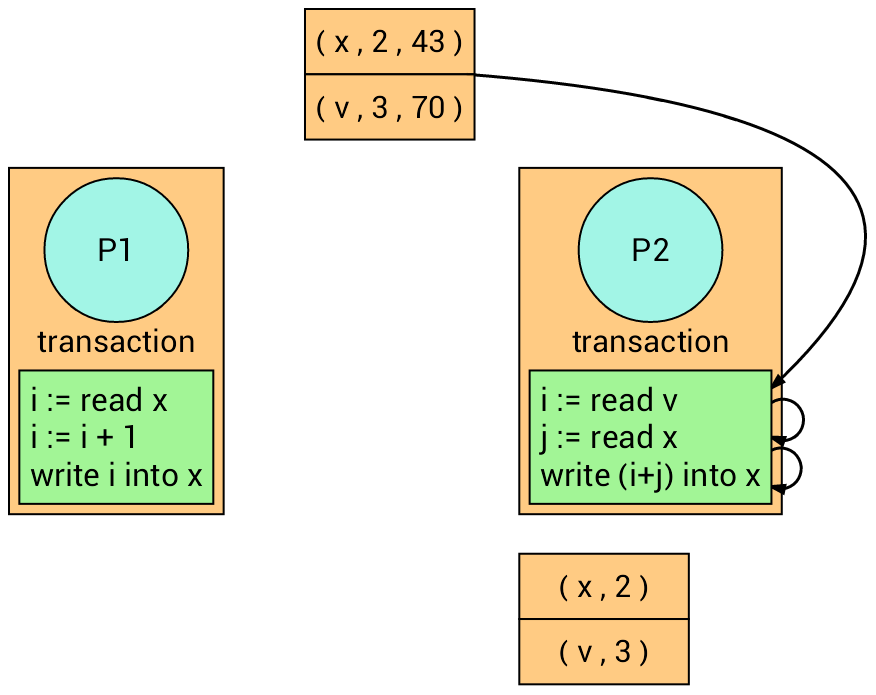
Example
We have two processes with two different transactions.
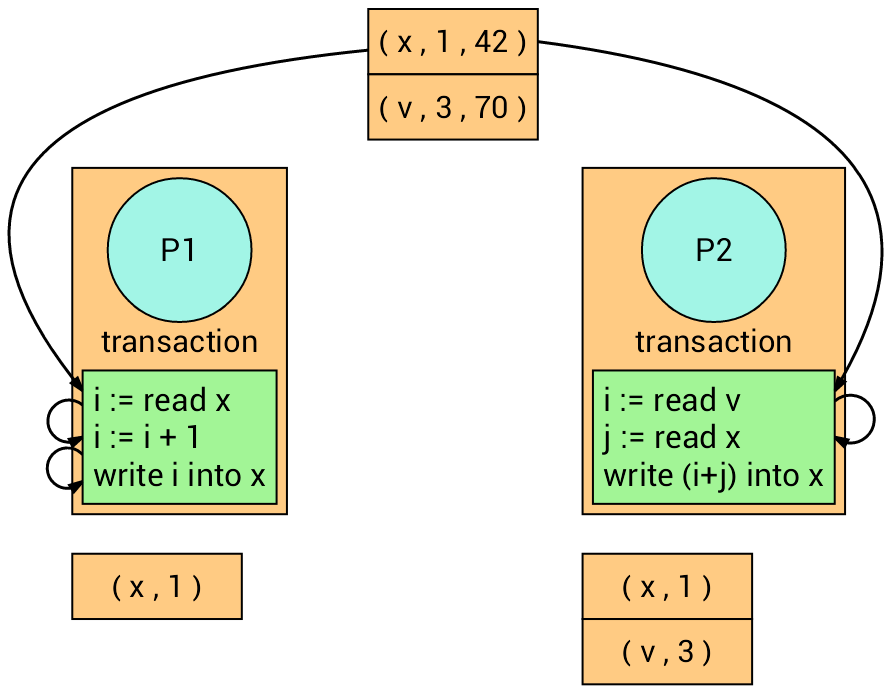
Now, both transactions read their corresponding variables. Each transaction recalls the version number of the read variables.
The transaction on the left firstly writes into variable x, and the
transaction on the right follows but it fails (Why?) and retry.
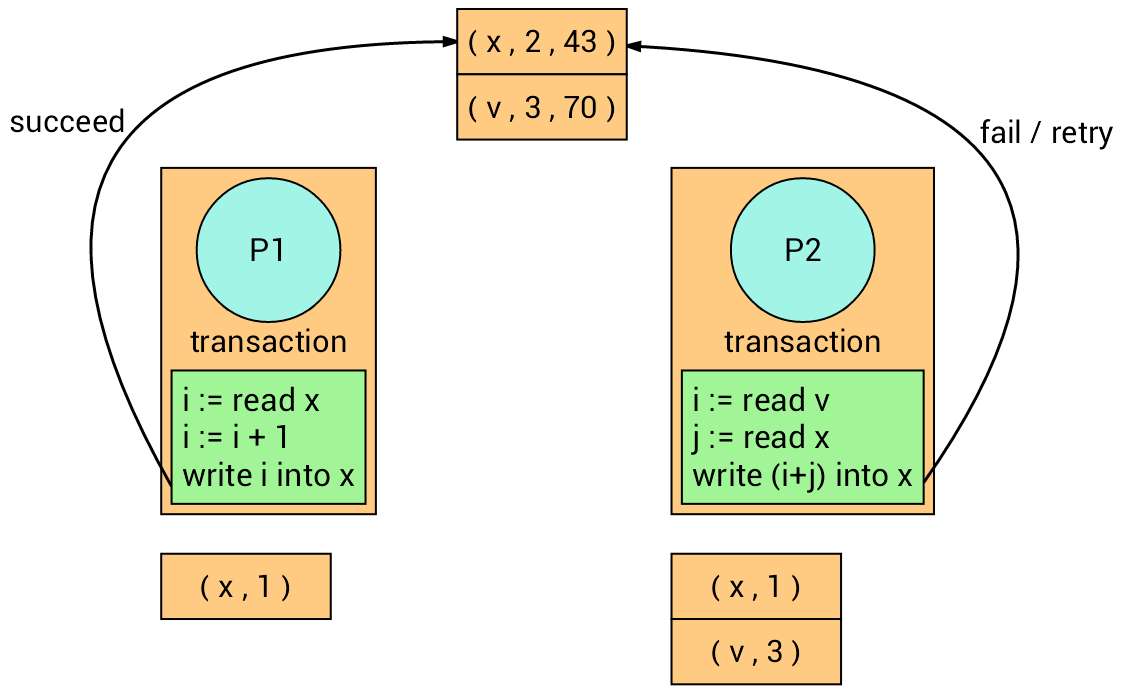
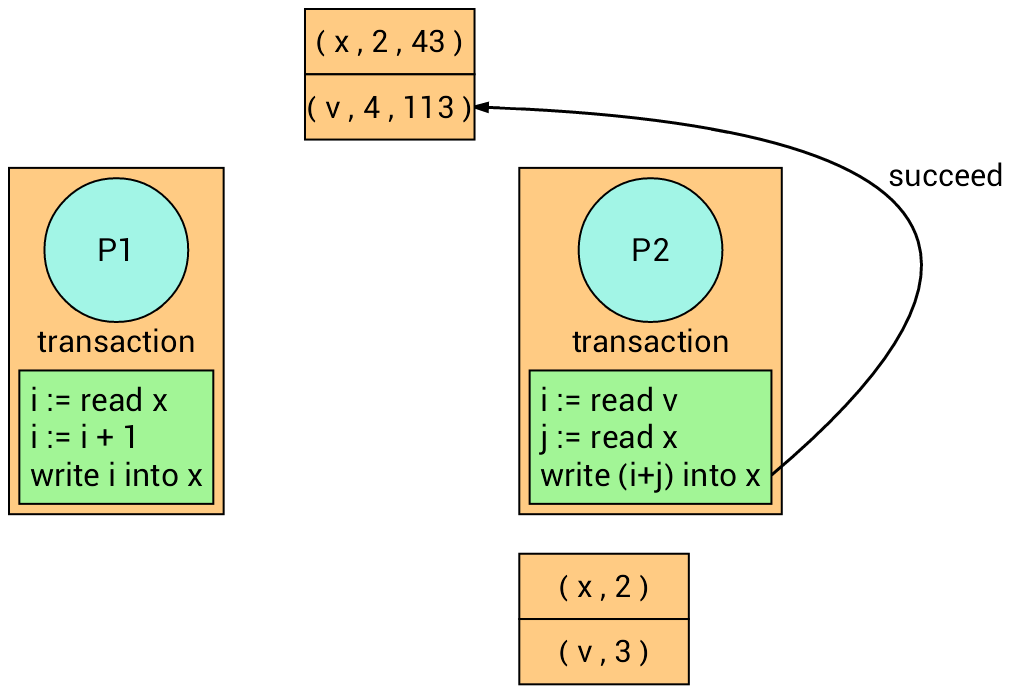
The transaction on the right retries.
At the time of writing, it succeeds (Why?).
Benefits of transactions:
Many processes can be in the critical section at the same time
More parallelism
They only need to rerun if there is an actual runtime conflict
Deadlocks cannot occur
Easy to compose
What is more:
retrymay block!- We can program everything that is possible with locks and condition variables
get() { if (beg == end) retry; T x = buf[beg]; beg = beg + 1 % S; }
...
atomic { ... x = m.get(); ... }
Implementations may provide an
orElseconditional construction for nested transactions- Try executing the first branch; if it succeeds without retrying then ignore the second branch
- Otherwise, roll back the effects run the second branch
Drawbacks of transactions:
Cannot guarantee fairness
- A large transaction can be starved by many small ones
All the book keeping can be expensive
STM are still a subject of reseach!