Feldspar: Functional Embedded Language for DSP and Parallelism
Emil Axelsson
AFP guest lecture, March 2013
Motivation
Feldspar was initiated by Ericsson and Chalmers with the aim to improve development of signal processing software
Why?
- New telecoms standards require ever-increasing computation power in radio base stations
- Limitations on power force movement to more and more parallel hardware
- Performance is essential!
- Portability is essential!
Motivation
Performance and portability essential
But
- Fast programs need to be highly optimized
- Optimization means target-specific
- Target-specific means non-portable
And
- Current signal processing code mostly written in C – not easily parallelized
Hand-optimized loop (from AMR codec)
ANSI-C specification:
for (j = 0; j < L_frame; j++, p++, p1++)
{
t0 = L_mac (t0, *p, *p1);
}
corr[i] = t0;
Equivalent loop optimized for specific processor:
#pragma MUST_ITERATE(80,160,80);
for (j = 0; j < L_frame; j++)
{
pj_pj = _pack2 (p[j], p[j]);
p0_p1 = _mem4_const(&p0[j+0]);
prod0_prod1 = _smpy2 (pj_pj, p0_p1);
t0 = _sadd (t0, _hi (prod0_prod1));
t1 = _sadd (t1, _lo (prod0_prod1));
p2_p3 = _mem4_const(&p0[j+2]);
prod0_prod1 = _smpy2 (pj_pj, p2_p3);
t2 = _sadd (t2, _hi (prod0_prod1));
t3 = _sadd (t3, _lo (prod0_prod1));
p4_p5 = _mem4_const(&p0[j+4]);
prod0_prod1 = _smpy2 (pj_pj, p4_p5);
t4 = _sadd (t4, _hi (prod0_prod1));
t5 = _sadd (t5, _lo (prod0_prod1));
p6_p7 = _mem4_const(&p0[j+6]);
prod0_prod1 = _smpy2 (pj_pj, p6_p7);
t6 = _sadd (t6, _hi (prod0_prod1));
t7 = _sadd (t7, _lo (prod0_prod1));
}
corr[i] = t0; corr[i+1] = t1;
corr[i+2] = t2; corr[i+3] = t3;
corr[i+4] = t4; corr[i+5] = t5;
corr[i+6] = t6; corr[i+7] = t7;
- Pragmas
- Intrinsic instructions
- Loop unrolling
- Etc.
Hand-optimized loop (from AMR codec)
Hand-optimized version probably not suited for a different processor; non-portable!
#pragma MUST_ITERATE(80,160,80);
for (j = 0; j < L_frame; j++)
{
pj_pj = _pack2 (p[j], p[j]);
p0_p1 = _mem4_const(&p0[j+0]);
prod0_prod1 = _smpy2 (pj_pj, p0_p1);
t0 = _sadd (t0, _hi (prod0_prod1));
t1 = _sadd (t1, _lo (prod0_prod1));
p2_p3 = _mem4_const(&p0[j+2]);
prod0_prod1 = _smpy2 (pj_pj, p2_p3);
t2 = _sadd (t2, _hi (prod0_prod1));
t3 = _sadd (t3, _lo (prod0_prod1));
p4_p5 = _mem4_const(&p0[j+4]);
prod0_prod1 = _smpy2 (pj_pj, p4_p5);
t4 = _sadd (t4, _hi (prod0_prod1));
t5 = _sadd (t5, _lo (prod0_prod1));
p6_p7 = _mem4_const(&p0[j+6]);
prod0_prod1 = _smpy2 (pj_pj, p6_p7);
t6 = _sadd (t6, _hi (prod0_prod1));
t7 = _sadd (t7, _lo (prod0_prod1));
}
corr[i] = t0; corr[i+1] = t1;
corr[i+2] = t2; corr[i+3] = t3;
corr[i+4] = t4; corr[i+5] = t5;
corr[i+6] = t6; corr[i+7] = t7;
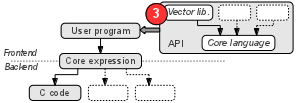
Code generation
(Old) Idea: Separate algorithm from optimizations
- Algorithm defined in a high-level, domain-specific language (DSL)
- General-purpose languages like Haskell normally not suited to run on embedded targets
Run-time too big, speed not optimal, etc.
- Optimizations defined separately, e.g. using annotations
- “unroll this loop 4 times”, “run this computation on a separate core”
- Code generator produces low-level, optimized code
Fast and portable code!
- Should (ideally) be able to generate the same code as hand-optimized
- Only annotations need to be changed when porting to new hardware
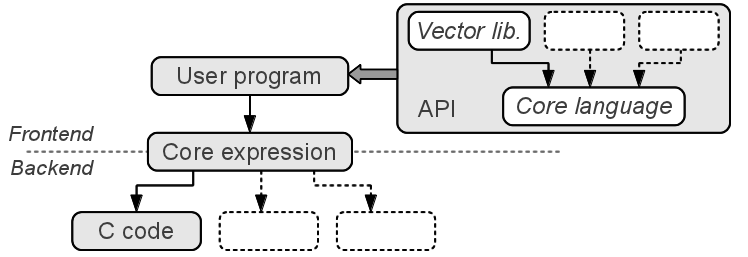
Feldspar – Functional Embedded Language for DSP and PARallelism
High-level DSL for numeric processing
Embedded in Haskell
- Implemented as a library in an existing language (host)
- Reusing existing infrastructure
- Parsing
- Type checking
- Module system
- Testing
- Packaging/building
- Etc.
More info on embedding: [Hudak1998, Elliott2003]
Feldspar – Functional Embedded Language for DSP and PARallelism
Language front-end:
- Embedded in Haskell
- Functional programming style (higher-order functions, polymorphism, etc.)
- Open set of domain-specific extra libraries
Back-ends:
- C code (can run on most targets)
- Future: LLVM, CUDA, FPGA
- Etc.
Example: distance between two points
File header:
import qualified Prelude as P
import Feldspar -- Core language
import Feldspar.Vector -- List-like data structure
import Feldspar.Compiler -- C code generator
type Point = (Data Float, Data Float)
dist :: Point -> Point -> Data Float
dist (x1,y1) (x2,y2) = sqrt (square (x1-x2) + square (y1-y2))
where
square x = x*x
- Removing the word
Data gives the same definition in ordinary Haskell
(Data is the AST of Feldspar expressions.)
Example: distance between two points
Interactive evaluation:
*Main> eval dist (5,10) (8,6)
5.0
Compilation:
*Main> icompile dist
...
void test(struct s_float_float_ * v0, struct s_float_float_ * v1, float * out)
{
float v2;
float v3;
v2 = ((* v0).member1 - (* v1).member1);
v3 = ((* v0).member2 - (* v1).member2);
(* out) = sqrtf(((v2 * v2) + (v3 * v3)));
}
Functional DSP
Typical DSP operations
- Element-wise multiplication: $x_i = a_i \cdot b_i$
- Moving average: $x_i = \frac{a_{i+1} + a_i}{2}$
- Scalar product: $x = \sum{a_i \cdot b_i}$
Exercise: Express as Haskell functions
elemMult :: [Float] -> [Float] -> [Float]
movingAvg :: [Float] -> [Float]
sProd :: [Float] -> [Float] -> Float
Functional DSP in
Haskell and Feldspar
Haskell:
elemMult :: [Float] -> [Float] -> [Float]
movingAvg :: [Float] -> [Float]
sProd :: [Float] -> [Float] -> Float
elemMult as bs =
movingAvg as =
sProd as bs =
Functional DSP in
Haskell and Feldspar
Haskell:
elemMult :: [Float] -> [Float] -> [Float]
movingAvg :: [Float] -> [Float]
sProd :: [Float] -> [Float] -> Float
elemMult as bs = zipWith (*) as bs
movingAvg as =
sProd as bs =
Functional DSP in
Haskell and Feldspar
Haskell:
elemMult :: [Float] -> [Float] -> [Float]
movingAvg :: [Float] -> [Float]
sProd :: [Float] -> [Float] -> Float
elemMult as bs = zipWith (*) as bs
movingAvg as = zipWith (\a a' -> (a+a')/2) (tail as) as
sProd as bs =
Functional DSP in
Haskell and Feldspar
Haskell:
elemMult :: [Float] -> [Float] -> [Float]
movingAvg :: [Float] -> [Float]
sProd :: [Float] -> [Float] -> Float
elemMult as bs = zipWith (*) as bs
movingAvg as = zipWith (\a a' -> (a+a')/2) (tail as) as
sProd as bs = sum $ zipWith (*) as bs
Feldspar:
elemMult :: Vector1 Float -> Vector1 Float -> Vector1 Float
movingAvg :: Vector1 Float -> Vector1 Float
sProd :: Vector1 Float -> Vector1 Float -> Data Float
elemMult as bs = zipWith (*) as bs
movingAvg as = zipWith (\a a' -> (a+a')/2) (tail as) as
sProd as bs = sum $ zipWith (*) as bs
Vector library
Inspired by Haskell’s list library:
type Vector1 a = Vector (Data a)
length :: Vector a -> Data Length
sum :: Numeric a => Vector (Data a) -> Data a
map :: (a -> b) -> Vector a -> Vector b
tail :: Vector a -> Vector a
(...) :: Data Index -> Data Index -> Vector (Data Index)
zipWith :: (Syntax b, Syntax a) =>
(a -> b -> c) -> Vector a -> Vector b -> Vector c
Example:
*Main> eval (sum $ map (*2) (1...10)) :: Int32
110
Modularity
Which one is most readable?
movingAvg :: Vector1 Float -> Vector1 Float
movingAvg as = zipWith (\a a' -> (a+a')/2) (tail as) as
movingAvg2 :: Vector1 Float -> Vector1 Float
movingAvg2 as = map (/2) $ zipWith (+) (tail as) as
movingAvg is perhaps closer to the specification: $x_i = \frac{a_{i+1} + a_i}{2}$
movingAvg2 is more modular!
- Computing result by transforming data in small steps
(“data-centric programming”)
- Reusing existing higher-order functions as much as possible
Loop fusion
Which one is most efficient?
movingAvg :: Vector1 Float -> Vector1 Float
movingAvg as = zipWith (\a a' -> (a+a')/2) (tail as) as
movingAvg2 :: Vector1 Float -> Vector1 Float
movingAvg2 as = map (/2) $ zipWith (+) (tail as) as
Loop fusion
*Main> icompile movingAvg
...
void test(struct array * v0, struct array * out)
{
uint32_t v2;
uint32_t len0;
v2 = getLength(v0);
len0 = min((v2 - min(v2, 1)), v2);
initArray(out, sizeof(float), len0);
for(uint32_t v1 = 0; v1 < len0; v1 += 1)
{
at(float,out,v1) = ((at(float,v0,(v1 + 1))
+ at(float,v0,v1)) / 2.0f);
}
}
Loop fusion
*Main> icompile movingAvg2
...
void test(struct array * v0, struct array * out)
{
uint32_t v2;
uint32_t len0;
v2 = getLength(v0);
len0 = min((v2 - min(v2, 1)), v2);
initArray(out, sizeof(float), len0);
for(uint32_t v1 = 0; v1 < len0; v1 += 1)
{
at(float,out,v1) = ((at(float,v0,(v1 + 1))
+ at(float,v0,v1)) / 2.0f);
}
}
- Both definitions result in the same C code!
- Vector operations fused into a single loop
- No intermediate data structures
Loop fusion
Feldspar’s vector library guarantees fusion!
- Predictable compilation
- Encourages modular data-centric programming
Removing dynamic length checks
Assume input vector of length 100:
*Main> icompile (movingAvg -:: newLen 100 >-> id)
...
void test(struct array * v0, struct array * out)
{
initArray(out, sizeof(float), 99);
for(uint32_t v1 = 0; v1 < 99; v1 += 1)
{
at(float,out,v1) = ((at(float,v0,(v1 + 1))
+ at(float,v0,v1)) / 2.0f);
}
}
More fusion
Two movingAvg filters in sequence:
*Main> icompile (movingAvg . movingAvg -:: newLen 100 >-> id)
...
void test(struct array * v0, struct array * out)
{
initArray(out, sizeof(float), 98);
for(uint32_t v1 = 0; v1 < 98; v1 += 1)
{
at(float,out,v1) = ((((at(float,v0,(v1 + 2))
+ at(float,v0,(v1 + 1))) / 2.0f)
+ ((at(float,v0,(v1 + 1))
+ at(float,v0,v1)) / 2.0f)) / 2.0f);
}
}
- Six additions and three divisions per iteration
- Fusion leads to recomputation
The force
Fusion can be prevented using “the force”:
force :: Syntax a => Vector a -> Vector a
- Semantically the identity function
- Operationally stores the vector in memory
The force
*Main> icompile (movingAvg . force . movingAvg -:: newLen 100 >-> id)
...
struct array v8 = {0};
...
for(uint32_t v6 = 0; v6 < 99; v6 += 1)
{
at(float,&v8,v6) = ((at(float,v0,(v6 + 1))
+ at(float,v0,v6)) / 2.0f);
...
for(uint32_t v5 = 0; v5 < 98; v5 += 1)
{
at(float,out,v5) = ((at(float,&v8,(v5 + 1))
+ at(float,&v8,v5)) / 2.0f);
...
- Two
+ and one / per iteration; twice as many iterations
- Allocates intermediate array
- Trades speed for memory
- The user is in control!
Code generation
Recall: Separate algorithm from optimizations
- Algorithm defined in a high-level, domain-specific language (DSL)
- Optimizations defined separately, e.g. using annotations
- Code generator produces low-level, optimized code
Feldspar
- High-level DSL
- Predictable compilation
- Functions like
newLen and force act as annotations
Integration with Haskell infrastructure
QuickCheck:
prop_movingAvg :: [Float] -> Property
prop_movingAvg a = P.not (P.null a) ==>
eval movingAvg a P.== eval movingAvg2 a
*Main> quickCheck prop_movingAvg2
+++ OK, passed 100 tests.
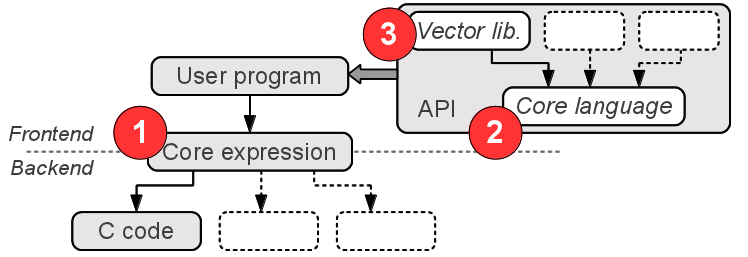
Architecture
- Abstract syntax tree data type (
Data a)
- User interface to the core AST
- High-level Haskell libraries
Core expressions
Feldspar uses a special representation of the AST (see part III)
However, the representation is isomorphic to a recursive data type:
data Data a
where
Literal :: (...) => a -> Data a
Add :: (Num a, ...) => Data a -> Data a -> Data a
Sub :: (Num a, ...) => Data a -> Data a -> Data a
Parallel :: (...) => Data Length
-> (Data Index -> Data a) -> Data [a]
...
- Note the use of higher-order abstract syntax (HOAST) for constructs that introduce variables (
ForLoop)
Core language
A large number of primitive functions, e.g:
not :: Data Bool -> Data Bool
(&&) :: Data Bool -> Data Bool -> Data Bool
(||) :: Data Bool -> Data Bool -> Data Bool
div :: Integral a => Data a -> Data a -> Data a
mod :: Integral a => Data a -> Data a -> Data a
instance Numeric a => Num (Data a)
...
- Many of these functions override the corresponding
Prelude functions
Core language
Complex constructs:
parallel :: Type a
=> Data Length -- Length of result
-> (Data Index -> Data a) -- Index projection
-> Data [a] -- Core language array
forLoop :: Type st
=> Data Length -- Number of steps
-> Data st -- Initial state
-> (Data Index -> Data st -> Data st) -- "Body" (single step)
-> Data st -- Final state
And much more…
Core language: Examples
Core language version of movingAvg:
movingAvg3 :: Data [Float] -> Data [Float]
movingAvg3 a = parallel (getLength a - 1) $ \i -> (a!(i+1) + a!i) / 2
Same C code as before
*Main> icompile (movingAvg3 -:: Feldspar.setLength 100 >-> id)
...
void test(struct array * v0, struct array * out)
{
initArray(out, sizeof(float), 99);
for(uint32_t v1 = 0; v1 < 99; v1 += 1)
{
at(float,out,v1) = ((at(float,v0,(v1 + 1))
+ at(float,v0,v1)) / 2.0f);
}
}
High-level libraries
The Syntax class abstracts over Data:
class Syntax a
where
type Internal a
desugar :: a -> Data (Internal a)
sugar :: Data (Internal a) -> a
instance Type a => Syntax (Data a)
where
type Internal (Data a) = a
desugar = id
sugar = id
High-level libraries
Vectors are syntactic sugar:
instance Syntax a => Syntax (Vector a)
where
type Internal (Vector a) = [Internal a]
...
Tuples are also sugar, etc.
Vector library
Type of vectors:
data Vector a
where
Indexed :: Data Length -> (Data Index -> a) -> Vector a
indexed :: Data Length -> (Data Index -> a) -> Vector a
indexed = Indexed
type Vector1 a = Vector (Data a)
type Vector2 a = Vector (Vector (Data a))
(The Vector type provided by Feldspar is slightly more complicated.)
- Implemented using the core language API
- Not part of the core expression data type
- Guaranteed to be reduced at compile-time
Vector library
A vector is not a core expression, but it can be turned into one:
length :: Vector a -> Data Length
length (Indexed l _) = l
index :: Vector a -> Data Index -> a
index (Indexed _ ixf) i = ixf i
freeze :: Type a => Vector (Data a) -> Data [a]
freeze (Indexed len ixf) = parallel len ixf
fold :: Syntax a => (a -> b -> a) -> a -> Vector b -> a
fold f init b = forLoop (length b) init $
\i st -> f st (index b i)
- Haskell functions that generate core expressions
- The polymorphic types
a and b are either core expressions or some other high-level type that can be turned into a core expression.
Exercises
Define:
tail :: Vector a -> Vector a
tail f (Indexed l ixf) = Indexed ...
map :: (a -> b) -> Vector a -> Vector b
map f (Indexed l ixf) = Indexed ...
take :: Data Length -> Vector a -> Vector a
take n (Indexed l ixf) = Indexed ...
zip :: Vector a -> Vector b -> Vector (a,b)
zip (Indexed l1 ixf1) (Indexed l2 ixf2) = Indexed ..
Vector fusion revisited
map (*2) . map (+3)
\(Indexed l ixf) -> map (*2) (map (+3) (Indexed l ixf))
\(Indexed l ixf) -> map (*2) (Indexed l ((+3) . ixf))
\(Indexed l ixf) -> Indexed l ((*2) . ((+3) . ixf))
\(Indexed l ixf) -> Indexed l (((*2) . (+3)) . ixf)
- Fusion happens in the vector library before any core expression is generated
- This is how fusion can be guaranteed!
Part III: Syntactic library
Slides from presentation of A generic abstract syntax model for embedded languages, ICFP 2012.
Back to Feldspar:
Implementation of parallel
- We will focus on what the Syntactic user has to write
- Ignore the magic that happens inside Syntactic
Implementation of parallel
Abstract syntax symbol:
data Array a
where
Parallel :: Type a => Array
( Length -- Number of elements
:-> (Index -> a) -- Index projection
:-> Full [a] -- Result
)
-- Other array constructs omitted
User interface (using type-class magic from Syntactic):
parallel :: Type a =>
Data Length -> (Data Index -> Data a) -> Data [a]
parallel = sugarSym Parallel
Implementation of parallel
Semantics:
instance Semantic Array
where
semantics Parallel = Sem "parallel"
(\len ixf -> genericTake len $ map ixf [0..])
Additionally: optimization, code generation: ≈ 30 LOC
Implementation of parallel
Summary: declarative implementation of parallel in ≈ 40 LOC
- Trivial boilerplate code omitted
What do we get?
- Strongly typed abstract and concrete syntax
- Interpretations:
- Evaluation
- Syntax tree rendering, etc.
- Transformations
- Constant folding
- Common sub-expression elimination
- Invariant code hoisting, etc.
Assembling the DSL
Feldspar expression type:
newtype Data a = Data { unData :: ASTF FeldDomain a }
The symbol domain:
newtype FeldDomain a =
FeldDomain (HODomain FeldSymbols Typeable Type a)
type FeldSymbols
= (Condition :|| Type)
:+: (Literal :|| Type)
:+: (Tuple :|| Type)
:+: (Array :|| Type)
:+: (Loop :|| Type)
:+: (NUM :|| Type)
:+: (BITS :|| Type)
:+: (Complex :|| Type)
...
Assembling the DSL
type FeldSymbols
= (Condition :|| Type)
:+: (Literal :|| Type)
:+: (Tuple :|| Type)
:+: (Array :|| Type)
:+: (Loop :|| Type)
:+: (NUM :|| Type)
:+: (BITS :|| Type)
:+: (Complex :|| Type)
...
The different “features” (e.g. Array) are developed independently and assembled “in the last minute”
- Simplifying cooperation and experimentation
- Enabling reuse across languages
References
Hudak. Modular Domain Specific Languages and Tools.
In ICSR ’98: Proceedings of the 5th International Conference on Software Reuse. 1998. IEEE Computer Society.
Elliott, Finne, de Moor. Compiling Embedded Languages.
Journal of Functional Programming. 2003. Cambridge University Press.